Machine learning is een tak van kunstmatige intelligentie die systemen in staat stelt te leren van data en voorspellingen of beslissingen te maken zonder expliciete programmering. Dit kennisbankartikel legt kernbegrippen, belangrijkste technieken, typische toepassingen en recente ontwikkelingen helder en zakelijk uit.
Wat is machine learning in één vraag?
Wat bedoelt men precies met machine learning, en waarmee verschilt het van andere vormen van softwareontwikkeling?
Kernpunten:
Machine learning is een vakgebied binnen AI dat statistische algoritmes gebruikt om patronen in data te leren en te generaliseren naar nieuwe data.
Belangrijke leerparadigma's zijn supervised learning, unsupervised learning, reinforcement learning en self-supervised learning.
Deep learning, op basis van neurale netwerken, domineert veel moderne toepassingen, waaronder beeldherkenning en taalmodellen.
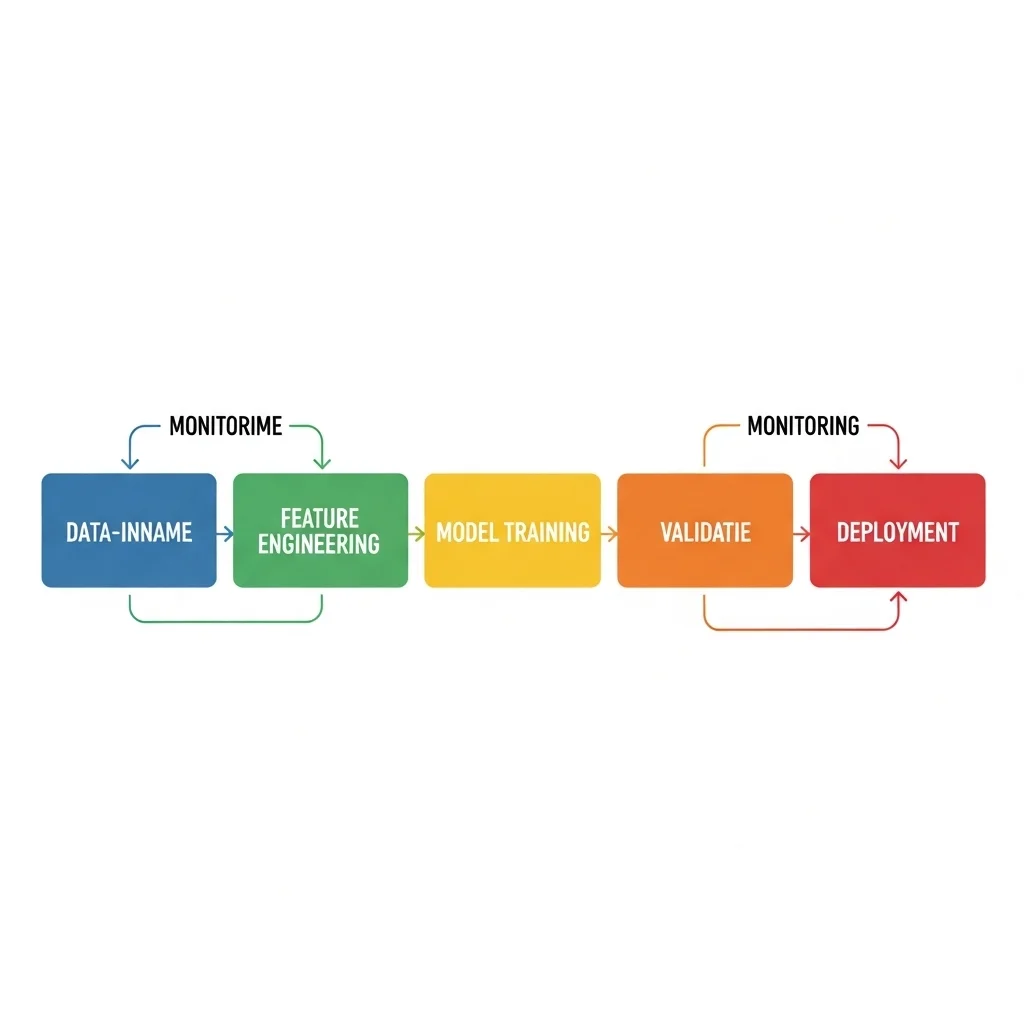
Implementatie vereist zorgvuldig datamanagement, modelvalidatie, monitoring en aandacht voor privacy en bias.
Actionable insight:
Begin met het definiëren van het businessdoel, zorg voor kwalitatieve data, kies eenvoudige modellen als benchmark, en schaal naar complexere technieken indien nodig. Zie ook de introductie voor organisaties op Starten met AI
Definitie en kernconcepten
Machine learning is het vakgebied binnen kunstmatige intelligentie dat zich bezighoudt met het ontwikkelen van algoritmes die automatisch patronen in data herkennen en vervolgens voorspellingen of beslissingen maken op basis van die patronen. In tegenstelling tot traditionele software, waarin gedrag expliciet wordt geprogrammeerd, leert een ML-systeem zijn gedrag uit voorbeelden en data, met als doel generalisatie naar nieuwe, onbekende situaties.
Belangrijke concepten zijn training, validatie en inferentie. Tijdens training optimaliseert een model zijn parameters op basis van een dataset. Validatie meet hoe goed dat model generaliseert, en inferentie is het proces waarbij het getrainde model voorspellingen doet op nieuwe data. Generalisatie, de kern van machine learning, is de mate waarin een model correcte voorspellingen blijft doen buiten de trainingsdata.
Typen machine learning en wanneer ze worden toegepast
Supervised learning gebruikt gelabelde data om een model te trainen voor voorspellende taken, zoals classificatie en regressie. Voorbeelden zijn spamdetectie, prijsvoorspelling en medische diagnose. Unsupervised learning zoekt naar structuur in ongelabelde data, typischerwijs voor clustering en dimensionale reductie, bijvoorbeeld klantsegmentatie of anomaly detection.
Reinforcement learning traint agents via beloningen en straffen, en is geschikt voor beslissingsproblemen met sequentiële acties, zoals robotica of trading. Zelflerende of self-supervised methoden extraheren supervisie uit ongeëtiketteerde data en vormen de basis voor veel moderne taalmodellen en foundation models.
Deep learning, als subdomein van ML, gebruikt diepe neurale netwerken en is effectief voor complexe datapleinen zoals afbeeldingen, audio en natuurlijke taal. Deze modellen vragen veel data en rekenkracht, maar bieden vaak superieure prestaties.
Praktische implementatie: data, modellen en validatie
Succes met machine learning start met data. Data moet representatief, schoon en voldoende groot zijn voor het gekozen model. Feature engineering, het omzetten van ruwe data naar modelvriendelijke kenmerken, blijft in veel toepassingen cruciaal, ook al verminderen sommige deep learning-methoden de noodzaak voor handmatige features.
Modelselectie en evaluatie hangen af van het probleem en de gewenste maatstaven. Bij classificatie worden metrics zoals nauwkeurigheid, precisie, recall en F1-score gebruikt. Bij regressie zijn RMSE en MAE gangbaar. Overfitting, wanneer een model te goed presteert op trainingsdata maar faalt op nieuwe data, wordt tegengegaan met technieken zoals regularisatie, cross-validation en meer data.
Voor productie is monitoring van modelperformance essentieel. Modellen verouderen wanneer data-distributies veranderen, daarom zijn pipelines voor retraining en MLOps-praktijken noodzakelijk. Voor implementatie van AI-oplossingen binnen bestaande systemen kan maatwerk-chatbots of systemen met retrieval augmented generation worden ontwikkeld, voorbeelden van toepassingen zijn te vinden bij AI-chatbot maatwerk en AI services
dataset = laad_data('train.csv')
model = init_model(architectuur='simple_nn')
for epoch in range(1, N_epochs+1):
batch_loss = 0
for batch in dataset.batches(size=32):
preds = model.forward(batch.inputs)
loss = loss_function(preds, batch.labels)
model.backward(loss)
model.update(learning_rate)
validate(model, validation_set)
save_model(model, 'model.pkl')
Risico's, ethiek en governance
Machine learning brengt technische en niet-technische risico's met zich mee. Bias in trainingsdata kan leiden tot discriminerende uitkomsten, en gebrek aan transparantie vermindert vertrouwen in beslissingen. Privacy is een belangrijk thema, vooral bij modellen die met persoonsgegevens werken. Regulering en governance zijn in opkomst, en organisaties dienen verantwoorde AI-principes en technische waarborgen op te nemen, zoals modelexplainability, data-minimalisatie en betrouwbare logging. Voor afwegingen rondom LLM data privacy, zie het artikel op Spartner
Recente ontwikkelingen tonen een snelle evolutie in foundation models en LLM's, wat nieuwe mogelijkheden creëert voor automatisering en slimme producten, en tegelijk beleidsmatige aandacht vereist rondom veiligheid en naleving.
REFERENCES
IBM, "What is Machine Learning (ML) ?" https://www.ibm.com/think/topics/machine-learning
Wikipedia, "Machine learning" https://en.wikipedia.org/wiki/Machine_learning
Microsoft Azure, "Wat is machine learning?" https://azure.microsoft.com/nl-nl/resources/cloud-computing-dictionary/what-is-machine-learning-platform
Spartner, relevante services en achtergrondartikelen: Starten met AI, AI-chatbot maatwerk, en LLM privacy afwegingen
Wat is het verschil tussen machine learning en kunstmatige intelligentie?
Machine learning is een subveld van kunstmatige intelligentie, gericht op het leren van algoritmes uit data. AI is een bredere term die alle technieken omvat waarmee systemen zelfstandig beslissingen kunnen nemen of taken uitvoeren, inclusief regelsystemen en symbolische AI.
Welke soorten problemen kunnen met machine learning worden opgelost?
Machine learning is geschikt voor voorspellende taken, patroonherkenning en het automatiseren van beslissingen, bijvoorbeeld voorspellen van klantgedrag, beeld- en spraakherkenning, detectie van fraude en aanbevelingssystemen.
Welke stappen zijn essentieel voordat modeltraining start?
Voorbereiding omvat het definiëren van het doel, verzamelen en analyseren van data, uitvoeren van data cleaning en feature engineering, en het opzetten van validatiesets en meetmethoden.
Hoe wordt overfitting voorkomen en hoe weet men dat een model generaliseert?
Overfitting wordt tegengegaan met technieken zoals cross-validation, regularisatie, vroegtijdig stoppen en het vergroten van datasetgrootte. Generalisatie wordt beoordeeld door prestaties op een gescheiden testset en door monitoring in productie.
Welke rol speelt deep learning binnen machine learning?
Deep learning gebruikt grote neurale netwerken en is krachtig voor ongestructureerde data zoals beelden, audio en tekst. Wanneer voldoende data en rekenkracht beschikbaar zijn, leveren deep learning-modellen vaak de beste prestaties.
Is machine learning geschikt voor elk bedrijf?
Machine learning is zinvol wanneer er relevante data beschikbaar is, een duidelijk te meten doel bestaat en de verwachte voordelen opwegen tegen de investeringen in data engineering en modelbeheer.
Wat zijn recente trends die de praktijk beïnvloeden?
Recente trends omvatten de verspreiding van grote taalmodellen en foundation models, verbeterde self-supervised trainingsmethoden en bredere adoptie van MLOps voor betrouwbaarheid.
Welke literatuur en bronnen zijn betrouwbaarder als startpunt?
Technische en praktijkgerichte bronnen zoals IBM's overzichtsartikel, Microsoft Azure documentatie en de encyclopedische toelichting op Wikipedia geven goede introducties.