Overzicht van natuurlijke taalverwerking
Natuurlijke taalverwerking is een deelgebied van kunstmatige intelligentie dat computers in staat stelt menselijke taal te analyseren, te begrijpen en te genereren. Het wordt toegepast in onder meer zoekmachines, chatbots, automatische vertalers en generatieve AI modellen.
In dit artikel worden de belangrijkste begrippen, technieken, modellen en toepassingen van NLP systematisch uitgelegd. Ook recente ontwikkelingen zoals large language models en retrieval augmented generation komen aan bod, evenals hun beperkingen en aandachtspunten rond privacy, bias en betrouwbaarheid.
Belangrijke inzichten in dit artikel:
Uitleg van de basisbegrippen rond NLP en het verschil met bredere AI en machine learning
Historisch overzicht van symbolische systemen, statistische modellen en deep learning
Beschrijving van kerntechnieken zoals tokenisatie, tagging, parsing, embeddings en transformerarchitecturen
Uitleg van large language models en retrieval augmented generation
Overzicht van typische toepassingen, van zoekmachines tot juridische en medische tekstanalyse
Belangrijkste uitdagingen, waaronder hallucinerende modellen, bias, veiligheid en regelgeving
Definitie en plaats van natuurlijke taalverwerking binnen AI
Natuurlijke taalverwerking, in het Engels natural language processing, is een deelgebied van kunstmatige intelligentie dat zich richt op het laten verwerken van menselijke taal door computers. Het doel is dat systemen tekst en spraak kunnen analyseren, interpreteren, genereren en er op een nuttige manier mee kunnen redeneren.
NLP bevindt zich op het snijvlak van informatica, taalkunde en statistiek. Vanuit de informatica komen data structuren, algoritmen en softwarearchitectuur. Vanuit de taalkunde komen inzichten in grammatica, semantiek en pragmatiek, bijvoorbeeld hoe zinnen zijn opgebouwd en hoe context betekenis beïnvloedt. Vanuit de statistiek en machine learning komen de methoden om patronen in grote hoeveelheden tekstdata te herkennen en te modelleren.
Binnen het bredere AI landschap vormt NLP een van de belangrijkste toepassingsgebieden. Veel generatieve AI systemen zijn in essentie NLP modellen die getraind zijn om tekst te voorspellen. Spraaksystemen combineren NLP met spraakherkenning en spraaksynthese. Taalmodellen worden bovendien steeds meer gebruikt als algemene redeneersystemen, ook buiten pure teksttoepassingen.
Basisbegrippen binnen NLP
Een aantal kernbegrippen komt in vrijwel elke NLP toepassing terug. Tokens zijn elementaire eenheden van tekst, bijvoorbeeld woorden of woorddelen. Tokenisatie is het proces waarmee ruwe tekst wordt opgesplitst in deze tokens. Een corpus is een grote verzameling tekst, vaak zorgvuldig samengesteld, waarop modellen worden getraind en geëvalueerd. Labels zijn de categorieën die een model leert voorspellen, bijvoorbeeld de taal van een tekst, het sentiment of de grammaticale functie van een woord.
Naast deze begrippen is er het onderscheid tussen gesuperviseerd en ongesuperviseerd leren. In gesuperviseerd leren wordt een model getraind op teksten met bekende labels, bijvoorbeeld e-mails die als spam of niet spam zijn geclassificeerd. In ongesuperviseerd leren zoekt een model zonder directe labels naar patronen in de data, bijvoorbeeld clusters van vergelijkbare woorden.
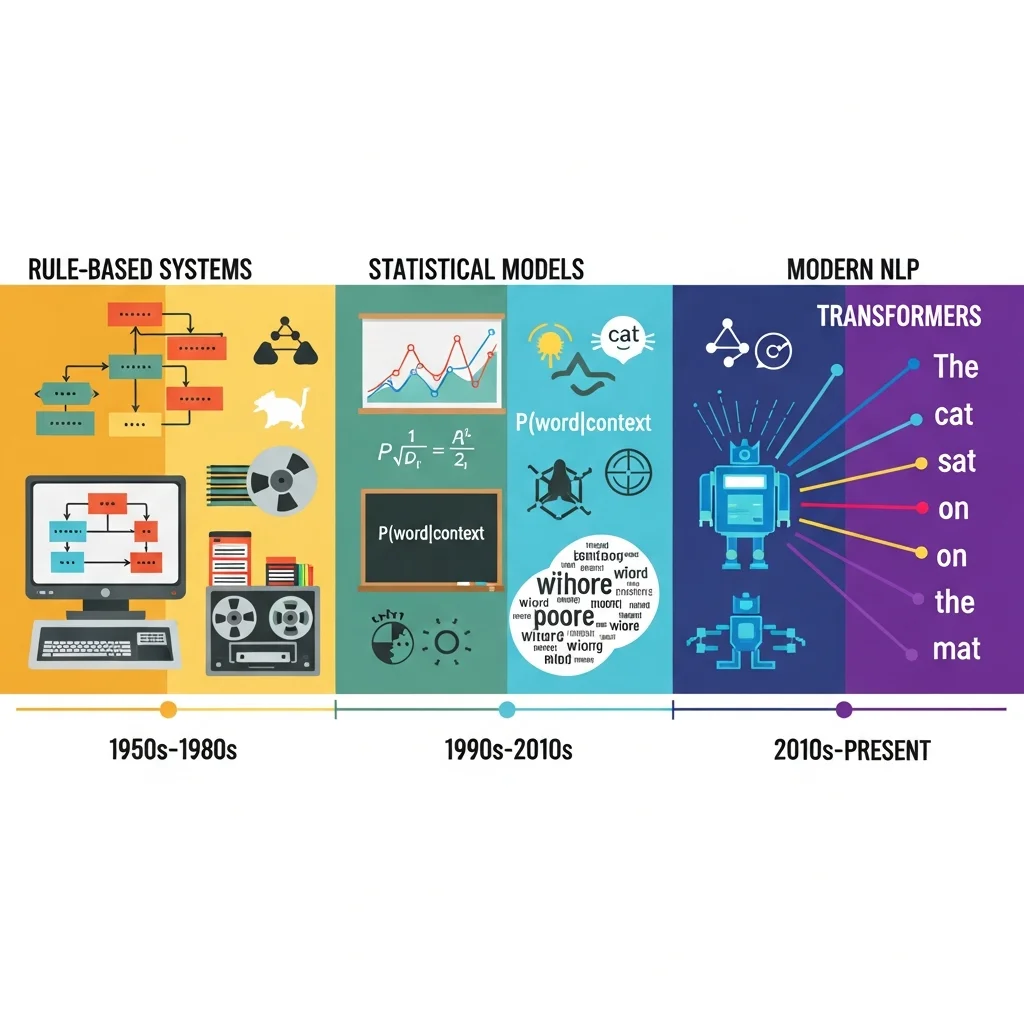
Historische ontwikkeling van NLP: van regels naar large language models
De geschiedenis van natuurlijke taalverwerking wordt vaak ingedeeld in drie hoofdperioden. De eerste periode werd gedomineerd door symbolische of regelgebaseerde systemen. In deze benadering leggen experts grammatica regels, woordenlijsten en semantische structuren handmatig vast. Vroege machinevertaling en grammatica checkers werkten op basis van zulke handmatige regels, wat tot beperkte dekking en matige schaalbaarheid leidde.
In de tweede periode verschoof de focus naar statistische NLP. Dankzij grotere tekstcorpora en snellere computers werden probabilistische modellen gangbaar, zoals n-gram taalmodellen en Hidden Markov Models. Deze modellen leren waarschijnlijkheden van woordvolgordes en labels uit data. Toepassingen zoals automatische spraakherkenning en probabilistische part of speech tagging werden hierdoor betrouwbaarder, al bleven ze vaak relatief oppervlakkig in hun begrip van context.
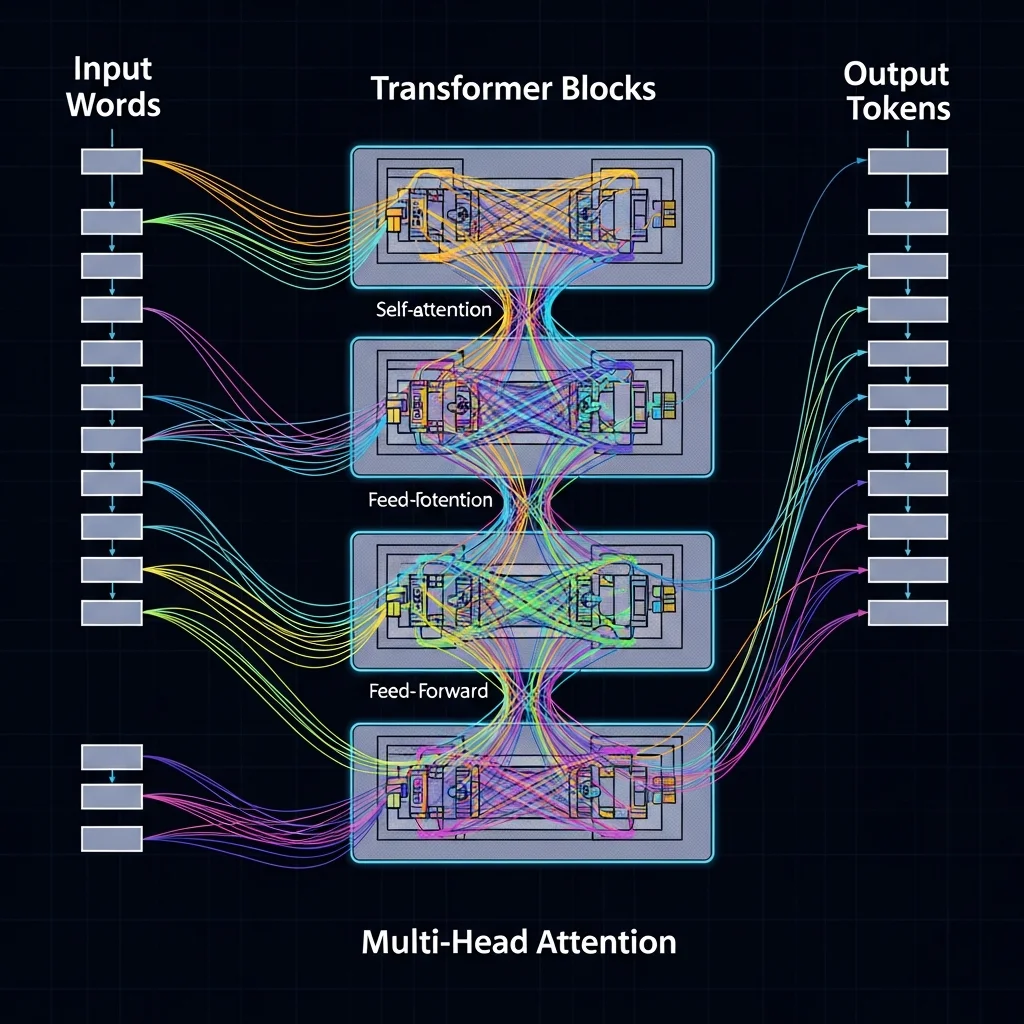
De derde periode, die nog steeds voortduurt, wordt gekenmerkt door deep learning. Eerst werden neurale netwerken ingezet voor specifieke taken zoals sentimentanalyse of vertaling. Daarna werd de transformerarchitectuur geïntroduceerd, een modeltype dat gebruikmaakt van attention mechanismen om relaties tussen woorden in een zin of document te leren, ongeacht de afstand ertussen. Dit maakte het mogelijk om grote, algemene taalmodellen te trainen die veel NLP taken in één keer aankunnen.
Een belangrijke recente stap is de opkomst van zogenaamde foundation models, vaak aangeduid als large language models. Deze modellen worden op zeer grote hoeveelheden tekst getraind, soms op honderden miljarden tokens. Ze zijn in staat om tekst te genereren, vragen te beantwoorden, code te schrijven en taken uit te voeren waarvoor ze niet expliciet zijn getraind. Omdat ze generiek en herbruikbaar zijn, vormen ze de basis voor tal van toepassingen in verschillende sectoren.
Architecturen en representaties
Moderne NLP modellen draaien om de representatie van taal in een vorm die geschikt is voor berekening. Eenvoudige modellen gebruikten bag of words, waarbij alleen werd geteld hoe vaak woorden voorkomen. Latere technieken introduceerden woordembeddings, vectorrepresentaties waarin woorden met een vergelijkbare betekenis dicht bij elkaar liggen. Modellen als Word2Vec en GloVe zijn bekende voorbeelden van zulke embedding methoden.
Transformergebaseerde modellen gaan nog een stap verder met contextual embeddings. Daarbij krijgt een woord een andere vectorrepresentatie afhankelijk van de context waarin het voorkomt. Het woord bank wordt bijvoorbeeld anders gerepresenteerd in de context van een financiële instelling dan in de context van een zitmeubel. Dit contextbewustzijn zorgt voor veel betere prestaties op complexe taal taken.
Kerntechnieken en typische NLP taken
NLP omvat een breed scala aan technieken en taken. Veel NLP pipelines beginnen met tekstvoorbewerking. Tokenisatie splitst tekst in tokens. Normalisatie zet tekst om naar een gestandaardiseerde vorm, bijvoorbeeld door alles naar kleine letters om te zetten of accenten te verwijderen. Stopwoordenverwijdering kan algemene woorden zoals de, het en een uitfilteren als ze voor een bepaalde taak weinig informatiewaarde hebben.
Een klassieke taak is part of speech tagging. Hierbij krijgt elk woord in een zin een label dat de grammaticale categorie aangeeft, zoals zelfstandig naamwoord, werkwoord of bijvoeglijk naamwoord. Deze informatie wordt vaak gebruikt als input voor complexere taken zoals syntactische ontleding. Parsing, of syntactische analyse, reconstrueert de grammaticale structuur van een zin in de vorm van een boom of afhankelijkheidsstructuur.
Semantische taken richten zich op betekenis. Named entity recognition identificeert en labelt entiteiten zoals personen, organisaties en locaties in tekst. Coreference resolution bepaalt welke verwijzende woorden, zoals hij en zij of dit bedrijf, betrekking hebben op dezelfde entiteit. Sentimentanalyse schat de houding of emoties in tekst, bijvoorbeeld positief, negatief of neutraal. Tekstclassificatie kent documenten toe aan vooraf gedefinieerde categorieën, zoals productreviews, juridische teksten of medische rapporten.
Veel moderne technieken zijn gebaseerd op neurale netwerken en worden vaak geïmplementeerd in frameworks voor deep learning. Een veelvoorkomend patroon is het gebruik van een vooraf getraind taalmodel, dat vervolgens wordt bijgeschaafd voor een specifieke taak. Een voorbeeld van zo een aanpak in codevorm is:
from transformers import AutoTokenizer, AutoModelForSequenceClassification\n\ntokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")\nmodel = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")\n\ninputs = tokenizer("This movie was surprisingly good", return_tensors="pt")\noutputs = model(**inputs)\nlogits = outputs.logits
In dit voorbeeld wordt een bestaand model voor sentimentanalyse gebruikt. De tekst wordt door de tokenizer omgezet naar modelinput, waarna het model een classificatie voorspelt.
Voor een meer visuele introductie zijn er online cursussen en colleges beschikbaar. Een veelbekeken collegereeks is bijvoorbeeld de introductielezing over NLP uit een gevorderd vak aan Carnegie Mellon University, die via YouTube te bekijken is via deze link: https://www.youtube.com/watch?v=MM48kc5Zq8A. Zulke colleges behandelen typische NLP taken, modelarchitecturen en evaluatiemethoden in meer technische diepgang.
Large language models, RAG en actuele aandachtspunten
Large language models domineren momenteel het NLP veld. Deze modellen worden getraind met de eenvoudige, maar krachtige doelstelling om het volgende token te voorspellen in een tekst. Door training op grote corpora leren ze patronen in taal die nuttig zijn voor een breed scala aan taken. Ze worden ingezet in chatinterfaces, code assistenten, zoeksystemen, vertalers en vele andere toepassingen.
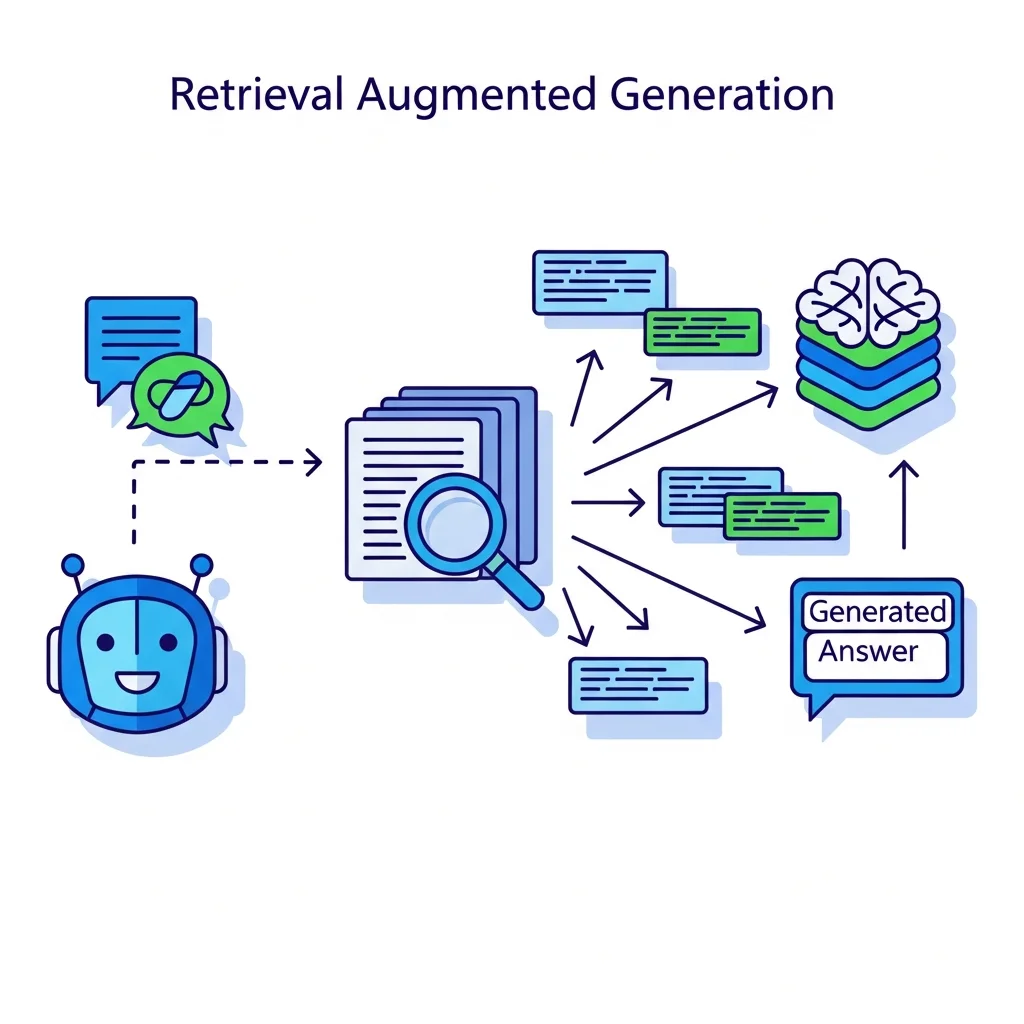
Een belangrijke uitdaging bij grote taalmodellen is het feit dat ze informatie soms plausibel verzinnen. Dit fenomeen wordt vaak hallucinerende antwoorden genoemd. Omdat het model patronen in tekst leert, maar geen directe toegangslaag heeft tot feitelijke databases, kan het fouten maken in feitelijke details, data en getallen. Om dit te mitigeren worden retrieval augmented generation technieken gebruikt. Daarbij combineert een systeem een taalmodel met een zoekcomponent die relevante documenten ophaalt. Het model genereert vervolgens antwoorden op basis van de opgehaalde context, wat de betrouwbaarheid en herleidbaarheid van de informatie kan verhogen.
Naast generatieve toepassingen blijven ook analytische toepassingen van NLP belangrijk. Hierbij wordt tekst niet alleen geproduceerd, maar vooral geanalyseerd om inzichten te destilleren. Voorbeelden zijn het detecteren van sentiment rond merken op sociale media, het herkennen van patronen in juridische uitspraken of het extraheren van klinische informatie uit medische dossiers. In dergelijke contexten zijn nauwkeurigheid, herhaalbaarheid en uitlegbaarheid cruciale kwaliteitscriteria.
Bij het gebruik van NLP spelen enkele bredere thema's een steeds belangrijkere rol. Ten eerste is er het vraagstuk van bias en discriminatie. Modellen leren patronen uit de data waarop ze getraind zijn, en als die data vooroordelen of scheve representaties bevatten, kunnen modellen die versterken. Ten tweede zijn er zorgen rond privacy, vooral bij toepassingen waarin gevoelige documenten of gesprekken worden verwerkt. Ten derde is er aandacht voor veiligheid en misbruik, bijvoorbeeld bij systemen die overtuigende misinformatie kunnen genereren.
Regelgeving en best practices ontwikkelen zich snel. Organisaties die NLP toepassen, krijgen in toenemende mate te maken met eisen op het gebied van transparantie, auditability en dataminimalisatie. Evaluatiemethoden richten zich daarom niet alleen meer op nauwkeurigheid of F1 scores, maar ook op robuustheid, fairness en naleving van juridische kaders.
Wat is natuurlijke taalverwerking precies?
Natuurlijke taalverwerking is het vakgebied binnen kunstmatige intelligentie dat zich bezighoudt met het laten verwerken van menselijke taal door computers. Het omvat alle technieken waarmee systemen tekst en spraak kunnen analyseren, begrijpen en genereren, zoals vertaling, tekstclassificatie en vraagantwoord systemen.
Hoe verschilt NLP van algemene AI of machine learning?
Machine learning is een verzamelnaam voor technieken waarmee systemen patronen leren uit data. NLP is een specifiek toepassingsgebied waarin de data taal is, bijvoorbeeld tekst of gesproken woorden. Veel NLP systemen gebruiken dus machine learning methoden, maar voegen daar taalkundige kennis en specifieke modelarchitecturen aan toe om met de complexiteit van taal om te gaan.
Welke typische toepassingen van NLP worden in organisaties gebruikt?
Veelgebruikte toepassingen zijn automatische vertaling, chatbots en virtuele assistenten, sentimentanalyse van klantfeedback, zoekmachines met semantisch begrip en automatische samenvatting van lange documenten. In sectoren zoals finance, legal, zorg en overheid worden NLP systemen bovendien gebruikt voor taken als contractanalyse, compliance monitoring, triage van dossiers en informatie extractie uit rapporten en formulieren.
Waarom zijn large language models zo belangrijk voor NLP?
Large language models zijn belangrijk omdat ze op grote schaal taalpatronen hebben geleerd en daardoor veel verschillende taken kunnen uitvoeren zonder dat elk afzonderlijk model opnieuw hoeft te worden ontworpen en getraind. Ze fungeren als generieke bouwsteen die met relatief weinig extra data kan worden aangepast aan een specifieke taak. Tegelijkertijd brengen ze nieuwe uitdagingen mee, zoals het risico op hallucinerende antwoorden, het moeilijker uitlegbaar maken van beslissingen en de noodzaak tot zorgvuldige omgang met vertrouwelijke data.
Wat is retrieval augmented generation in de context van NLP?
Retrieval augmented generation is een architectuur waarbij een taalmodel wordt gecombineerd met een zoekcomponent. Eerst worden documenten of passages opgehaald die relevant zijn voor een vraag, daarna genereert het model een antwoord op basis van deze specifieke context. Dit helpt om antwoorden beter te onderbouwen met bronmateriaal en kan factuele nauwkeurigheid en herleidbaarheid verhogen, mits de onderliggende documentcollectie zorgvuldig is samengesteld en onderhouden.
Hoe wordt de kwaliteit van NLP systemen gemeten?
De kwaliteit van NLP systemen wordt gemeten met taak specifieke metrics. Voor classificatieproblemen worden vaak nauwkeurigheid, precisie, recall en F1 score gebruikt. Voor vertaling bestaan er metrics zoals BLEU en COMET. Voor generatieve taken spelen menselijke evaluaties een grote rol, bijvoorbeeld beoordelingen van coherentie, relevantie en factualiteit. Steeds vaker worden ook fairness, robuustheid en veiligheid expliciet meegenomen in de evaluatie om de maatschappelijke impact beter te beoordelen.
Welke risico's en beperkingen hebben NLP systemen?
Belangrijke risico's zijn bias in de output, fouten in feitelijke informatie, gevoeligheid voor adversarial input en ongewenst gebruik, bijvoorbeeld voor het genereren van misleidende content. Daarnaast hebben modellen vaak een beperkte transparantie, waardoor het lastig is om precies te begrijpen waarom een bepaald antwoord is gegeven. Deze beperkingen betekenen dat NLP systemen meestal als ondersteuning worden ingezet en dat menselijke controle bij kritieke beslissingen wenselijk blijft.
Hoe verhouden NLP en spraakherkenning zich tot elkaar?
Spraakherkenning zet gesproken taal om naar tekst, terwijl NLP die tekst vervolgens kan analyseren en verwerken. In een spraakgestuurde assistent worden deze componenten gecombineerd. Eerst herkent een spraaksysteem de woorden, daarna interpreteert een NLP component de betekenis, bepaalt een systeem de reactie en wordt via spraaksynthese een gesproken antwoord teruggegeven. Hoewel spraakherkenning en NLP verschillende technische uitdagingen kennen, zijn ze in moderne AI oplossingen vaak nauw met elkaar verweven.