“Het OpenAI vinkje zegt toch dat ze niet trainen op onze API-data, klopt dat?”
Goede vraag. Maar het echte risico zit eigenlijk niet zozeer in modeltraining.. het zit in logs, retentie en menselijke fouten. Net zoals in de Cloud?
Twijfel jij ook?
Wat betekent "niet trainen" nu precies?
OpenAI, Google, Microsoft en xAI beloven geen training op jouw data – mits het bewuste vinkje uit staat.
Een eigen LLama-instantie op je server elimineert het dataverlatings-risico, maar levert (nog) wat in op accuratesse.
Het vertrouwen in cloud-tools lijkt op het vertrouwen dat we al jaren in Office 365 en Google Workspace leggen.
Spartner's Mind AI-platform helpt je het juiste LLM-spoor te kiezen, zonder dataverlies of lock-in.
Praktische inzichten die je straks meeneemt:
Checklist om de privacy-claims van AI-providers te valideren
Beslissingsmatrix: cloud-model vs. on-premise model
Tips om een hybride setup te draaien (best of both worlds)
Concrete valkuilen uit onze praktijk 🚧
Vertrouwen of controleren?
Dataeigenaar blijft altijd verantwoordelijk
Provider-belofte Veel leveranciers claimen: "We trainen niet op API-data". Controleer of dit standaard is of opt-in/opt-out. Scope: alleen modeltraining, óók logs?
On-premise optie LLama-modellen (2 en recenter 3) kun je on-device draaien. Zo verlaat data nooit je netwerk. Nadeel: meer beheer, vaak minder up-to-date.
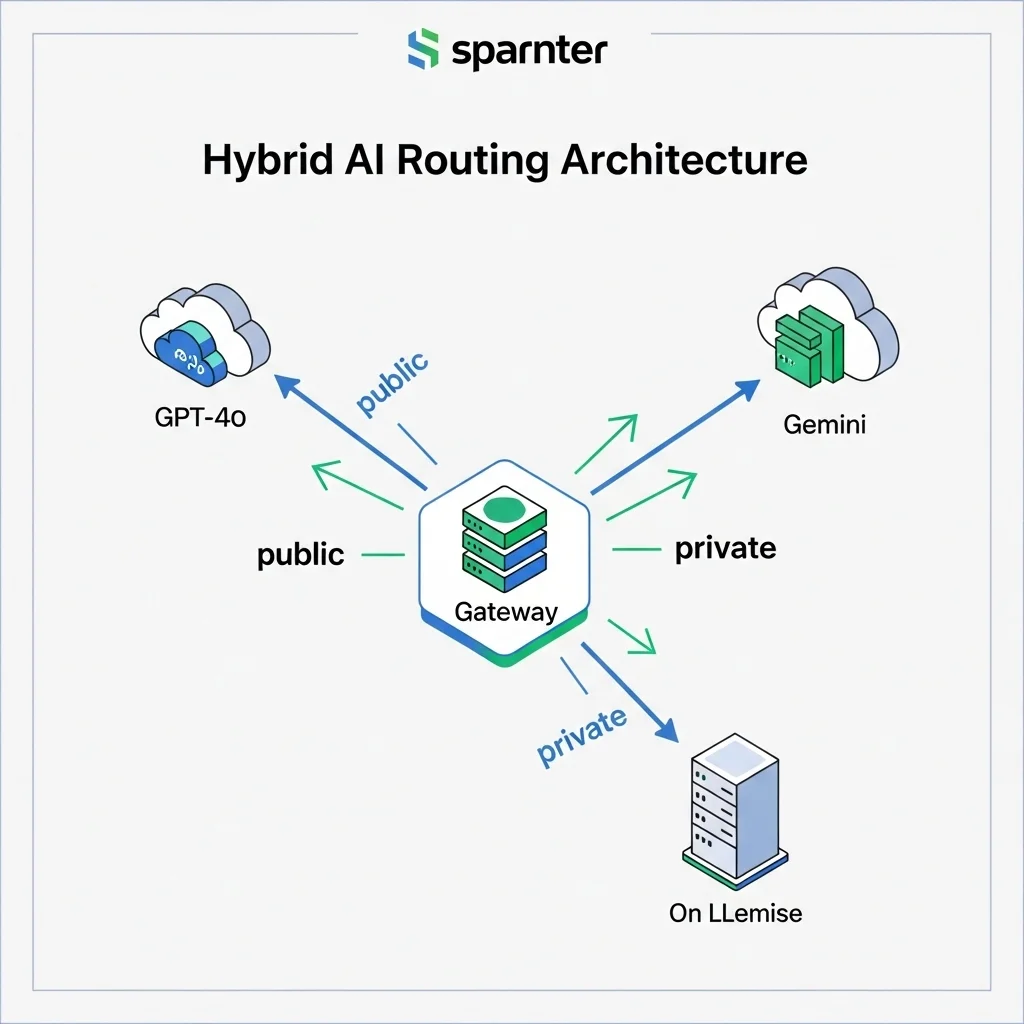
Hybride pad Combineer publieke high-end modellen voor generieke prompts en lokale LLama voor gevoelige context. Routing automatiseren is key.
Governance first Stel beleid op vóór je prompts schrijft. Wie mag wat versturen? Hoe lang worden transcripts bewaard? Encryptie end-to-end?
Inventariseer en valideer: de stappen
Inventariseer je dataklassen
Wat is publiek, intern, vertrouwelijk, strikt vertrouwelijk?
Wij gebruiken hiervoor een simpele label-matrix die met kleurcodes in de prompt belandt.
Valideer providerclaims
Test een lokale LLama-pilot
Meet kwaliteitsgap
Gebruik een golden-set van eigen voorbeelden.
Scoreer op factuality, tone-of-voice en hallucinations.
Maak een hybride router
Onze aanpak: een lightweight API-gateway die op basis van datalabel en prompttype routeert naar GPT-4o, Gemini 1.5 of LLama-3-70B-Instruct.
Valstrik: log sanitization niet vergeten!
Benieuwd welke route het beste past bij jullie data-strategie? Drop je vraag hieronder of plan direct een koffiemomentje – ik denk graag mee ☕.
Het privacy-statement van de Big Four
Mooie woorden, maar wat zegt de kleine lettertjes?
OpenAI – Sinds maart 2023 traint OpenAI níet meer op API-data. ChatGPT-data wordt wél voor fine-tuning gebruikt, tenzij je in het settings-menu het vinkje "Chat history & training" uitzet. Bij de Enterprise-licentie staat het standaard uit.
Microsoft – In Azure OpenAI geldt "your prompts, your completions, your data". Data blijft in jouw tenant, wordt niet gebruikt voor modeltraining én wordt veertien dagen gelogd voor abuse-monitoring – encrypted at rest.
Google – Gemini 1.5 claims geen enterprise-data in hun trainings-pipeline op te nemen. De organisatie hanteert wel live-metrics, maar deze worden geanonimiseerd.
xAI – Groeibriljantje Grok focust op publieke X-data. API-data van klanten belandt in een silo zonder read-rechten voor het trainings-team, aldus hun whitepaper van juli 2025.
"LLM-safety equals cloud-trust. Als je al jaren SharePoint vertrouwt, is dit technisch hetzelfde vertrouwen – maar wel met een krachtigere contentprocessor erachter."
LLama lokaal: minder glans, meer grip
Wat levert een eigen server je écht op?
Laatst draaiden we LLama-3-8B op een Mac Studio om marketing-copy te genereren voor een interne campagne. Resultaat? Acceptabel, maar niet verbluffend. Toen we dezelfde prompt door GPT-4o stuurden, kregen we nuances en culturele verwijzingen die LLama miste.
De afweging:
Security: Data blijft binnen je LAN, dus geen DPA-hoofdpijn.
Performance: Zwaarder model? Dan GPU-budget en energie-rekening omhoog.
Maintenance: Zelf patchen, updaten, kwantisatie-trucs toepassen.
Quality: LLama 3-70B komt in de buurt van GPT-3.5, maar 4o-niveau is nog ver weg.
Een prettige middenweg is quantized LLama 3-13B (Q4-K). Die draait op een enkele high-end GPU en scoort in onze tests 82 % van GPT-4o op factuality bij technische Q&A's – genoeg voor interne kennisbanken.
Hybride architectuur in de praktijk
Hoe wij het bij klanten oplossen
We hebben Mind AI zo gebouwd dat elke prompt eerst door een "sensitivity classifier" gaat. Score boven de drempel? Dan route naar lokale LLama, anders naar een public API. Logging gebeurt in een versleutelde vector-database, wegschrijf-retentie twaalf uur.
```php
$route = classify($prompt);
switch($route){
case 'private': return llama_local($prompt);
case 'public': return gpt4o_cloud($prompt);
}
```
Zo combineer je het beste van twee werelden zonder continu te wisselen tussen tooling.
Business-perspectief: wat kost vertrouwen?
Risico, reputatie en ROI
Organisaties investeren miljoenen in ISO-certificeringen om klantvertrouwen te winnen. Toch sturen medewerkers soms gedachteloos gevoelige info naar ChatGPT. Beleid alléén is dus niet genoeg; tooling moet meedenken.
Shadow AI ontstaat razendsnel. Een verbod werkt averechts, faciliteren is slimmer.
ROI van een on-premise model wordt pas positief als je dagelijks duizenden prompts verstuurt.
Compliance-druk (NIS2, DORA) versnelt de vraag naar audit-trails binnen LLM-workflows.
Strategische tip: Bereken niet alleen GPU-kosten, maar ook de waarde van sneller besluitvorming door high-end modellen. Soms verdient extra databeveiliging zich terug in één incident dat niét gebeurt.
Kan ik OpenAI gebruiken voor privacy-gevoelige data als ik het vinkje uitzet?
Ja, technisch gezien gaat jouw prompt dan niet de trainingsset in. Uit onze ervaring blijkt dat de grootste risico's daarna vooral in log-retentie en menselijke fouten zitten.
Is een lokale LLama altijd veiliger?
Valt mee 😊. Als je geen solide netwerksegregatie hebt, kan een on-premise model juist méér attack-surface bieden dan een streng beheerde cloud-tenant.
Hoe groot is het kwaliteitsverschil tussen GPT-4o en LLama-3-70B?
In onze benchmarkset (500 NL/EN prompts) scoorde GPT-4o 94 % op factuality, LLama-3-70B 86 %. Voor brainstorms is dat prima, voor juridisch advies te laag.
Moet ik ieder model afzonderlijk DPIA'en?
Niet persé. Je kunt een overkoepelende Data Protection Impact Assessment doen en daarin per model een risicoprofiel opnemen. Scheelt papierwerk.
Hoe zit het met latency bij lokale modellen?
Met een moderne GPU zit LLama-3-13B rond 1 s per 250 tokens. Via de cloud haal je 250-500 ms. Of dat acceptabel is, hangt af van je use-case.
Wat als policies morgen veranderen?
Stel WAF-regels en alerts in op policy-URLs van je provider. Zo spot je wijzigingen binnen een uur. We doen dit zelf met een simpele diff-checker 👀.
Kan ik mijn eigen data toevoegen aan een cloudmodel zonder dat het uitlekt?
Ja, via "retrieval-augmented generation" (RAG). Je houdt de data in je vector-DB, het model krijgt alleen embeddings in context.
Hoe helpt Spartner hierin?
We hebben Mind AI, een platform waarin je met één click switcht tussen GPT-4o, Gemini, LLama of Grok. Plus: ingebouwde governance-laag die audit-logs en dataclassificatie regelt.
Ik hoor graag: hoe maken jullie de afweging tussen cloud-gemak en on-premise grip? Deel je gedachte telefonisch of plan een sparsessie op kantoor – koffie staat klaar! ☕