Machine learning zet data om in waarde zonder dat er handmatig wordt geprogrammeerd voor elke beslissing. In dit kennisbank artikel lees je hoe de techniek werkt, welke leervormen er zijn en welke recente doorbraken de versnelling verklaren.
Overzicht
Machine learning in drie minuten
Machine learning is het vakgebied binnen kunstmatige intelligentie dat algoritmes leert patronen te herkennen en beslissingen te nemen op basis van data. Het veld ontwikkelt zich razendsnel door krachtige hardware, grote dataverzamelingen en geavanceerde neurale netwerken. Recente voorbeelden, zoals Google Gemini die astronomische beelden classificeert met slechts vijftien voorbeelden, onderstrepen de snelheid van innovatie.
Belangrijkste punten:
Definitie, geschiedenis en relatie met AI
Verschillende leertypes (supervised, unsupervised, reinforcement)
Concrete algoritmes, van beslisbomen tot transformer netwerken
Kwaliteitsrisico's zoals bias en overfitting
Nieuwe trends, waaronder multimodale LLM-systemen en edge learning
Fundament en definitie
Machine learning is een verzamelnaam voor statistische methoden die automatisch patronen vinden in gegevens en op basis daarvan voorspellingen doen. Het principe werd in 1959 geïntroduceerd door IBM-onderzoeker Arthur Samuel. Sindsdien is de techniek geëvolueerd tot een kerncomponent van moderne software, variërend van spamfilters tot autonome voertuigen.
Historische context en relatie met AI
Na pionierswerk in de jaren vijftig en zestig concentreerde de aandacht zich in de jaren tachtig op neurale netwerken. De grote doorbraak kwam rond 2012, toen deep-learning modellen dankzij GPU's en data-sets als ImageNet spectaculaire resultaten boekten. Machine learning wordt vaak gezien als onderdeel van kunstmatige intelligentie, waarin AI het brede doel is om menselijke intelligentie te evenaren, terwijl machine learning zich richt op leertechnieken gebaseerd op data.
Leervormen en algoritmes
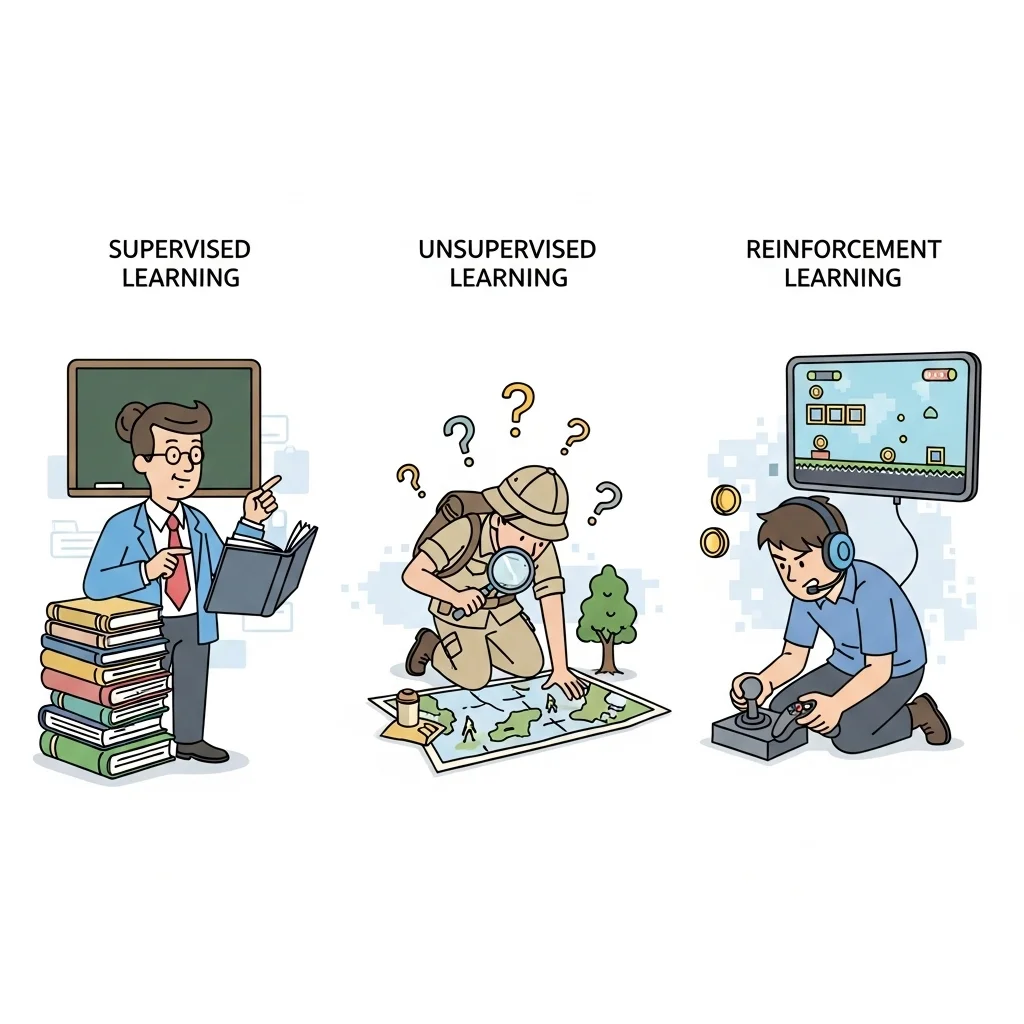
Elke praktijktoepassing berust op een van drie leerstrategieën.
Supervised learning
Hier krijgt het algoritme gelabelde voorbeelden (inputs met bijbehorende outputs). Modellen als beslisbomen, random forests en neurale netwerken vallen in deze categorie. Ze excelleren in classificatie en regressie, bijvoorbeeld het voorspellen van churn of het herkennen van afbeeldingen.
Unsupervised learning
Wanneer labels ontbreken zoekt het model naar verborgen structuren. Clustering-algoritmes (k-means of DBSCAN) en dimension-reductie methoden (PCA, t-SNE) ontdekken segmenten of verkleinen complexe data voor visualisatie.
Reinforcement learning
Deze methode leert via beloningen en straffen. Het is succesvol in robotics en spel-AI. Een agent optimaliseert een sequentiële beslissing, vergelijkbaar met hoe een schaakprogramma leert via zelfspel.
Recente innovaties en praktijkcases
Machine learning evolueert door betere hardware, open source libraries en nieuwe architecturen zoals transformers.
Multimodale LLM-assistent in de astronomie
Op 8 oktober 2025 publiceerden de Universiteit Oxford en Google Cloud een studie waarin Gemini, een generiek large language model, met slechts vijftien voorbeelden echte astronomische transiënten wist te onderscheiden van ruis met 93 procent nauwkeurigheid. Het model gaf bovendien leesbare verklaringen voor zijn keuzes, wat de transparantie verhoogt. Deze doorbraak toont dat kleine datasets geen showstopper meer vormen en versnelt "human-in-the-loop" workflows.
Edge en embedded learning
Dankzij gespecialiseerde chips zoals TPUs en neuromorfe hardware draaien modellen lokaal op apparaten. Dat maakt realtime analyse mogelijk in industrie-omgevingen of medische wearables.
Kwaliteitsaspecten en risico-mitigatie
Machine learning is krachtig maar niet foutloos.
Bias, overfitting en explainability
Een model kan vooringenomen beslissingen nemen als trainingsdata scheef is. Overfitting ontstaat wanneer het model te nauwgezet de trainingsdata kopieert en slecht generaliseert. Moderne frameworks zoals SHAP en LIME helpen verklaringen te genereren en vergroten vertrouwen.
Governance en compliance
Wetgeving vraagt om inzicht in beslislogica, zeker bij hoog-risico toepassingen. Een gestructureerde AI-governance aanpak, zoals beschreven in grip op AI governance, helpt organisaties om ethische en juridische eisen te borgen.
Wat is het verschil tussen machine learning en kunstmatige intelligentie?
Kunstmatige intelligentie is het overkoepelende doel om computergestuurde systemen slim te laten handelen. Machine learning is een subset die statistische methoden gebruikt om te leren van data.
Hoeveel data is nodig om te starten?
Uit praktijkervaring blijkt dat een paar duizend gelabelde voorbeelden vaak voldoende is voor tabulaire problemen. Voor beeld en taal ligt de grens hoger, tenzij transfer learning of generieke LLM's worden ingezet, zoals het Gemini-voorbeeld uit oktober 2025.
Wat zijn de populairste programmeertalen voor machine learning?
Python domineert door bibliotheken als TensorFlow, PyTorch en scikit-learn. In de Laravel-wereld wordt PHP in combinatie met Python-services gebruikt om modellen te integreren, zie onze aanpak bij starten met AI.
Kan machine learning lokaal draaien op embedded hardware?
Ja, frameworks zoals TensorFlow Lite en ONNX Runtime maken het mogelijk om modellen te comprimeren en op microcontrollers te draaien. Dit is handig voor IoT-sensoren waar latency en privacy cruciaal zijn.
Hoe wordt de kwaliteit van een model gemeten?
Gangbare metrics zijn accuracy, precision, recall en F1 score. Bij regressieproblemen worden MSE of MAE toegepast. Uit onze ervaring is het essentieel om naast kwantitatieve metrics ook explainability checks uit te voeren om onverwachte bias vroeg op te sporen.
Welke rol speelt data-governance in machine learning projecten?
Data-governance waarborgt dat de juiste data beschikbaar, betrouwbaar en compliant is. Zonder heldere governancestructuur loop je risico op datalekken of onbetrouwbare inzichten, wat bij audits of ISO-certificering direct zichtbaar wordt.
Is machine learning toepasbaar voor kleine en middelgrote bedrijven?
Absoluut. Door cloud-services en kant-en-klare modellen dalen de instapkosten. Platforms zoals Mind integreren meerdere AI-aanbieders en maken het mogelijk om zonder diepgaande data science kennis geavanceerde analyses uit te voeren. :)
Hoe snel veroudert een model?
Dat verschilt per domein. Bij snel veranderende data, zoals financiële transacties, kan drift al na weken optreden. In stabielere omgevingen, bijvoorbeeld industriële sensorgegevens, blijft een model maanden tot jaren bruikbaar. Monitoring en periodieke retraining zijn daarom standaardpraktijk.