Deep learning is een subset van machine learning die gebruikmaakt van diepe neurale netwerken om complexe patronen te herkennen. Dit kennisbankartikel beschrijft kernbegrippen, architecturen, trainingsprincipes, toepassingen en belangrijke beperkingen op een zakelijke en feitelijke manier.
Waarom is deep learning relevant voor organisaties en ontwikkelteams?
Deep learning maakt het mogelijk om ongestructureerde data, zoals afbeeldingen, tekst en audio, op schaal te analyseren en te transformeren naar bruikbare output. Dit levert praktische voordelen op voor automatisering, besluitvorming en productinnovatie.
Kernpunten
Definitie en basisconcepten, inclusief neurale lagen, activatiefuncties en backpropagation.
Veelgebruikte architecturen, zoals convolutionele netwerken, recurrente netwerken en transformer-gebaseerde modellen.
Trainingspraktijken, datasetvereisten en evaluatiecriteria.
Toepassingen en bekende beperkingen, inclusief bias, explainability en rekenkosten.
Actionable insight
Bij implementatie eerst de datakwaliteit en businesswaarde vaststellen.
Overweeg pre-trained modellen en fine-tuning als effectieve route voor productintegratie.
Neem governance en privacymaatregelen vroeg in het project op.
Wat is deep learning en hoe verhoudt het zich tot machine learning
Deep learning is een onderdeel van machine learning dat modellen met vele verwerkingslagen gebruikt, de zogenaamde diepe neurale netwerken. Deze netwerken leren representaties van data op verschillende abstractieniveaus, waardoor ze complexe patronen kunnen vangen die klassieke methoden niet makkelijk vinden. In technische termen bestaat een diep netwerk uit opeenvolgende lineaire transformaties gevolgd door niet-lineaire activaties, en de parameters van die transformaties worden geleerd via optimalisatie, meestal door gradient descent en backpropagation.
Belangrijke verschillen met traditionele machine learning zijn onder meer de mate van feature engineering en schaalbaarheid. Waar traditionele methoden veel handmatige voorbewerking vereisen, kunnen diepe netwerken ruwe of licht voorbewerkte data effectief verwerken, mits voldoende voorbeelden beschikbaar zijn. Dit maakt deep learning bijzonder geschikt voor taken als beeldherkenning, spraaktranscriptie en natuurlijke taalverwerking, toepassingen die tegenwoordig veel aandacht krijgen in zowel onderzoek als industrie.
Kerncomponenten van een diep neuraal netwerk
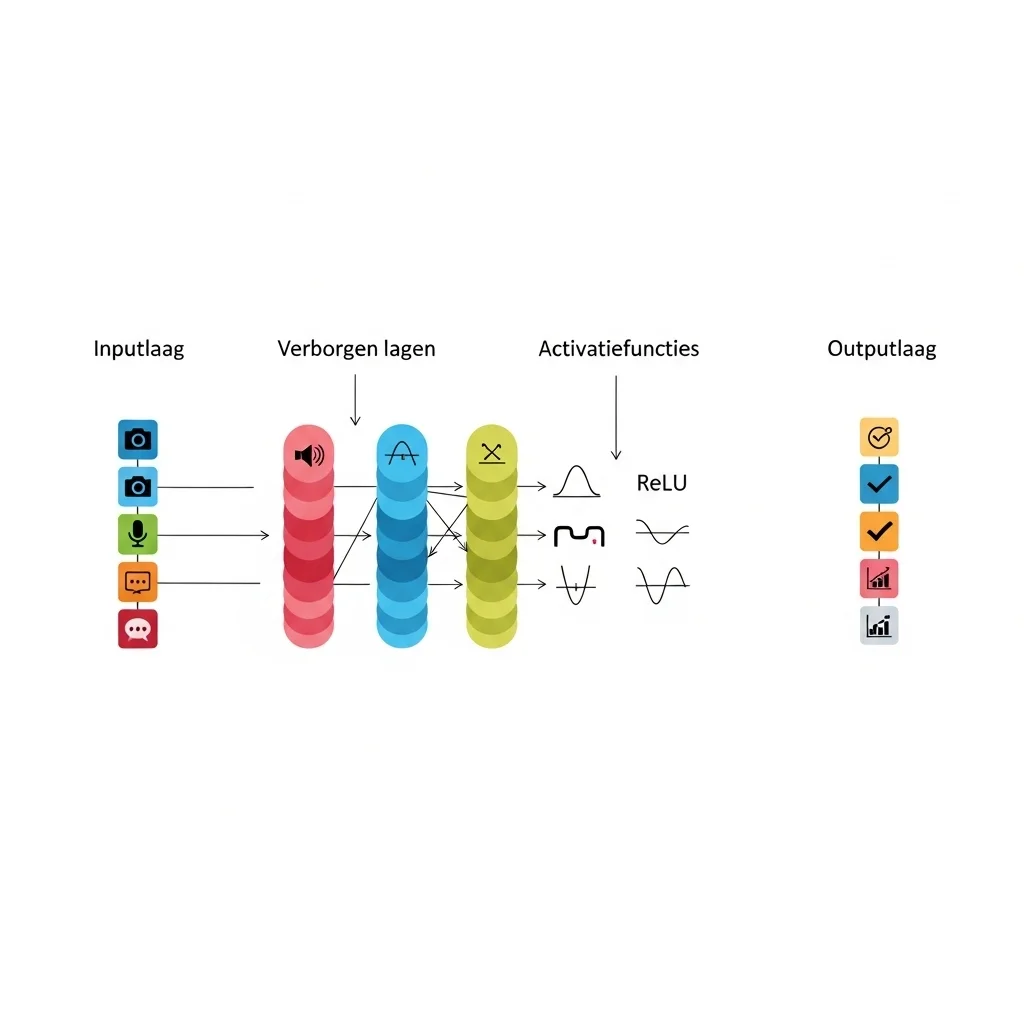
Een typisch diep model bevat inputlagen, verborgen lagen en een outputlaag, elke laag bestaande uit neuronen die gewogen sommatie en activatie uitvoeren. Activatiefuncties zoals ReLU, sigmoid en softmax bepalen de niet-lineariteit van het netwerk. Voor trainingsstabiliteit en betere convergentie worden technieken toegepast zoals batchnormalisatie, dropout en gewichtsregularisatie.
Het leerproces draait om een verliesfunctie die het modelgedrag kwantificeert en een optimizer die parameterupdates bepaalt. Veelgebruikte optimalizers zijn stochastic gradient descent met momentum, Adam en RMSprop. Voor succesvolle training is het bovendien cruciaal om hyperparameters zorgvuldig te kiezen, waaronder learning rate, batchgrootte en architectuurtemplates zoals laagdiepte en breedte. Deze keuzes bepalen in sterke mate de generalisatiecapaciteit van het model naar nieuwe gegevens.
Architecturen en hun typische toepassingen
Convolutionele neurale netwerken, vaak afgekort tot CNN's, zijn optimaal voor beeld- en videosignalen, doordat convoluties lokale patronen en translatie-invariantie vastleggen. Recurrente netwerken en varianten zoals LSTM en GRU werden traditioneel gebruikt voor sequentiedata, bijvoorbeeld tijdreeksen en tekst. Sinds enkele jaren domineren transformer-gebaseerde modellen de natuurlijke taalverwerking en worden ze steeds vaker toegepast in multimodale taken, vanwege hun vermogen om langeafstandsrelaties in data te modelleren.
Naast deze klassieke types bestaan er specifieke architecturen voor taken zoals objectdetectie, semantische segmentatie, en generatieve modellen. Generative adversarial networks en diffusion models zijn voorbeelden van structuren die gebruikt worden om nieuwe, realistische samples te genereren, en dragen aanzienlijk bij aan toepassingen in media- en creatieve industrie.
Trainingsdata, rekenkracht en evaluatiecriteria
De prestaties van diepe modellen zijn sterk afhankelijk van datasetgrootte en diversiteit. Voor veel toepassingen bieden voorgetrainde modellen en transfer learning een praktische route, omdat deze modellen reeds algemene representaties hebben geleerd op grote datasets en met relatief weinig extra data kunnen worden aangepast voor specifieke taken. Belangrijke stappen in het datapreparatieproces zijn annotatiekwaliteit controleren, representativiteit verifiëren en biasrisico's evalueren.
Rekenkosten blijven een belangrijke overweging. Training van grote modellen kan aanzienlijke GPU- of TPU-resources vergen, en de operationele kosten na uitrol wegen mee in architectuurbeslissingen. Voor productieomgevingen zijn latency, throughput en schaalbaarheid relevante metrics. Evaluatie gebruikt doorgaans gescheiden testsets, cross-validation en metrics die passen bij de taak, zoals accuracy, F1-score, ROC-AUC voor classificatie, en mean average precision voor detectie.
Veiligheid, privacy en ethische aspecten
Bij inzet van deep learning in zakelijke contexten zijn governance, privacy en explainability onmisbaar. Modellen kunnen biases reproduceren of versterken die aanwezig zijn in trainingsdata, wat tot ongelijke outcomes kan leiden. Regelgevingskaders en privacy-eisen zoals GDPR vereisen dat data minimalisatie, purpose limitation en passende beveiliging worden toegepast. Technische mitigaties omvatten data-anonimisering, fairness-audits en het gebruik van explainability-methoden zoals SHAP en LIME voor inzicht in modelgedrag.
Voor organisaties is het raadzaam om modellen niet los te zien van de besluitprocessen waar ze onderdeel van zijn. Een governance-structuur inclusief documentatie, versiebeheer en monitoring na uitrol helpt risico's te beheersen en continu te verbeteren. Verdere richtlijnen voor governance en praktische implementaties van AI-projecten worden beschreven in relevante artikelen en workshops over AI-governance, zie ook het overzicht op de Spartner site, bijvoorbeeld de pagina over grip op AI governance.
Relevante technologieën en integratie in softwareprojects
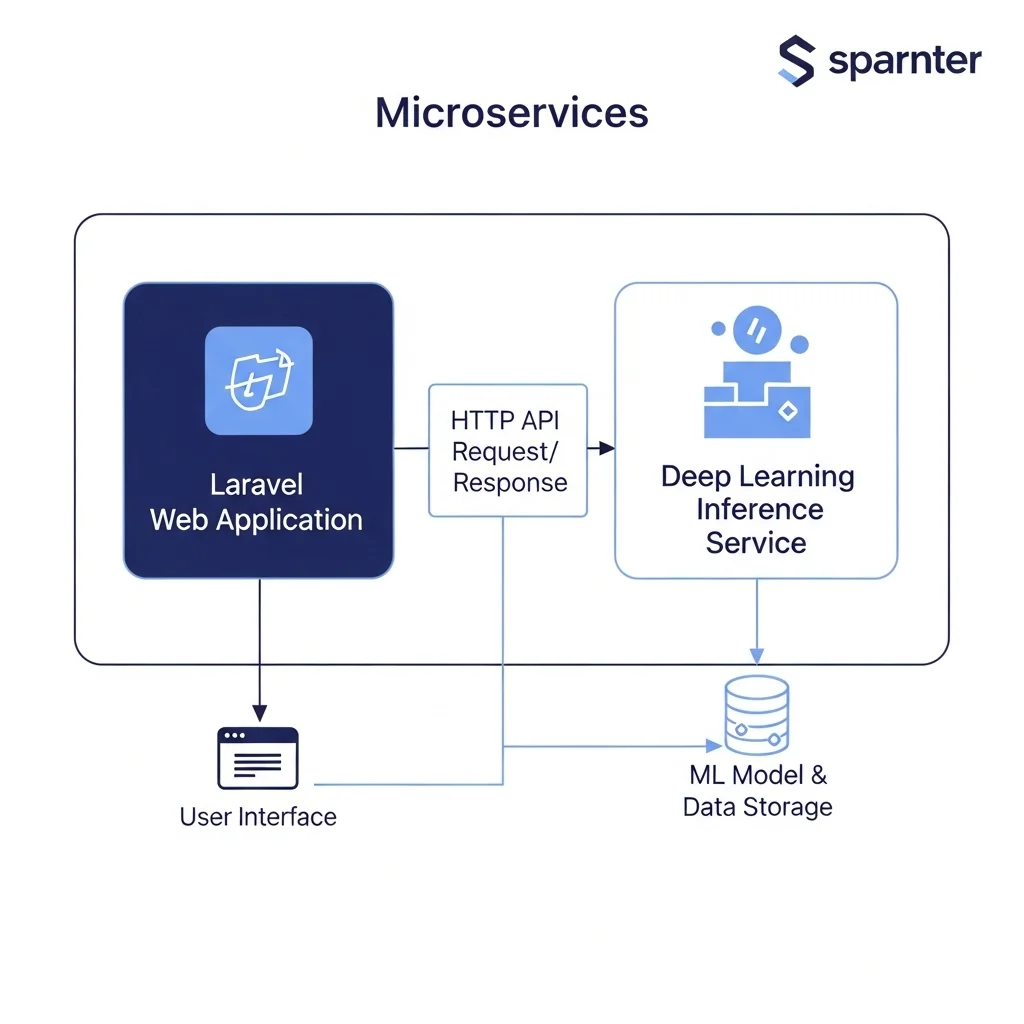
Integratie van deep learning in bestaande applicaties vereist technische keuzes op het vlak van model deployment en API-architectuur. Gebruik van modelserving frameworks, containerisatie en schaalbare inferentieplatforms maakt het mogelijk om modellen betrouwbaar te draaien in productie. Voor veel zakelijke toepassingen is het efficiënt om inference te scheiden van de hoofdapplicatie, en te werken met asynchrone queues of microservices voor zware verwerkingstaken.
Voor teams die met Laravel en moderne webstacks werken, is koppeling mogelijk via HTTP-API's of dedicated microservices. Spartner documenteert voorbeelden van AI-integratie en productisatie op de site, waaronder oplossingen voor chatbots en geautomatiseerde content workflows, zie de pagina over AI-chatbot maatwerk en de intro pagina starten met AI. Voor contentproductie en SEO-gebaseerde workflows biedt automatische integratie van AI-systemen kansen om repetitieve taken te versnellen, zoals beschreven op de pagina AI content maken.
Belangrijke overwegingen bij integratie zijn modelversiebeheer, monitoring van drift in de data distributie, en rollback- of fallback-mechanismen wanneer modelgedrag onverwachte output produceert. Deze operationele aspecten zijn cruciaal voor duurzame inzet.
Wat is het belangrijkste verschil tussen machine learning en deep learning?
Machine learning omvat een breed scala aan methoden waarbij een model patronen leert uit data. Deep learning is een subset die gebruikmaakt van diepe neurale netwerken met meerdere lagen. Deze netwerken leren hiërarchische representaties waardoor ze complexere taken aankunnen, vaak met minder handmatige feature engineering.
Welke datahoeveelheid is minimaal nodig voor succesvol deep learning?
Er bestaat geen vaste ondergrens, maar in de praktijk geldt dat meer data doorgaans beter is. Voor specialistische taken kan transfer learning uitkomst bieden, waarbij een voorgetraind model met een beperkte aanvullende dataset wordt gefinetuned. Uit onze ervaring blijkt dat voor veel commerciële toepassingen enkele honderden tot enkele duizenden representatieve voorbeelden al waardevolle resultaten opleveren, mits de voorbeelden van hoge kwaliteit zijn. 🙂
Welke frameworks worden het meest gebruikt voor deep learning?
Veel gebruikte frameworks zijn momenteel PyTorch en TensorFlow, vanwege hun volwassen ecosysteem en ondersteuning voor zowel onderzoek als productie. Daarnaast bestaan er hogere abstractielaagtools en model serving oplossingen die deployment vereenvoudigen. Keuze hangt af van bestaande infrastructuur, benodigde schaal en teamexpertise.
Hoe kan bias in een deep learning-model worden gedetecteerd en verminderd?
Detectie begint met dataset-analyse, stratificatie en fairness-metrics. Technische mitigaties omvatten data-augmentatie, herweging van trainingssamples en adversarial debiasing. Governancemaatregelen zoals onafhankelijke audits en transparante documentatie over dataset- en modelkeuzes zijn essentieel om risico's structureel te verminderen.
Welke rol spelen transformer-modellen in moderne deep learning toepassingen?
Transformer-architecturen hebben de natuurlijke taalverwerking radicaal veranderd en vinden nu ook toepassing in multimodale en vision-taken. Dankzij hun aandachtmechanismen kunnen transformers langeafstandsrelaties modeleren en schalen naar zeer grote modellen. Ze vormen de technische basis voor veel voorgetrainde modellen die in productie worden ingezet, en zijn vaak de eerste keuze bij taken die contextuele begrip vereisen.
Wat zijn praktische stappen om te starten met deep learning in een organisatie?
Eerst de businesscase valideren en de data beschikbaarheid beoordelen. Vervolgens een proof of concept opzetten met een klein team, gebruikmakend van voorgetrainde modellen wanneer mogelijk. Parallel aan technische ontwikkeling dient governance ingericht te worden, inclusief privacy-eisen en monitoring. Voor begeleiding bij implementatie en prototyping zijn er ook externe workshops en consultancy opties, een voorbeeld van zulke diensten staat op de Spartner pagina over AI-workshop. 🙂
Hoe wordt de kwaliteit van een deep learning-model beoordeeld in productie?
Kwaliteit wordt gemeten op task-specifieke metrics, additioneel op monitoring van performance-gedrag zoals latency en foutpercentages. Post-deploy monitoring voor data drift, performance degradatie en gebruikersfeedback vormt een integraal onderdeel van kwaliteitsborging. Automatische retraining en alerts bij afwijkingen zijn aanbevolen operationele maatregelen.
Zijn er kant-en-klare oplossingen voor bedrijven die geen eigen ML-team hebben?
Ja, er bestaan managed AI-diensten en prebuilt oplossingen voor veelvoorkomende use cases, zoals beeldclassificatie, transcriptie en sentimentanalyse. Voor maatwerk toepassingen verdient het de voorkeur om te starten met een beperkte integratie van voorgetrainde modellen en deze stapsgewijs uit te breiden, waarbij externe expertise kan helpen bij architectuurkeuzes en governance. Zie ook het overzicht van AI-automatiseringen op de Spartner site, waaronder AI-oplossingen voor contentproductie en servicedesk automation, via AI content maken en AI-email servicedesk ontwikkelen.