Machine learning is een onderdeel van kunstmatige intelligentie dat computers in staat stelt patronen te leren uit data en voorspellingen te doen zonder expliciete regels. Dit kennisbankartikel legt op zakelijke wijze de kernconcepten, werkwijze, belangrijke toepassingsgebieden en recente ontwikkelingen uit.
Samenvatting
Hebt u zich ooit afgevraagd hoe systemen zonder expliciete programmering toch betrouwbare voorspellingen kunnen doen? Machine learning is de tak van de informatica die dit mogelijk maakt, door statistische modellen te trainen op voorbeelden in plaats van regels te coderen.
Kernpunten
Definitie en positie binnen AI, inclusief onderscheid met traditionele softwareontwikkeling.
Belangrijkste soorten machine learning, typische algoritmen en een beknopt trainingsproces.
Toepassingen in de praktijk, evaluatiecriteria en veelvoorkomende risico's zoals bias en data leakage.
Recente ontwikkelingen en relevantie voor moderne LLM-gedreven oplossingen, met verwijzing naar actuele discussies rond modelkwaliteit en governance.
Actionable insight
Voor een verantwoord projectstart, begin met een duidelijke data-audit en business objective, kies een passende modelklasse, en definieer expliciet meetcriteria voor succes.
Wat is machine learning
Machine learning is een discipline binnen kunstmatige intelligentie die zich richt op het ontwikkelen van algoritmen die leren van data. In plaats van dat elke beslissing in code wordt vastgelegd, optimaliseert een model parameters op basis van voorbeelden, zodat het vervolgens voorspellingen of classificaties kan uitvoeren op nieuwe, ongeziene data.
Het onderscheid met traditionele softwareontwikkeling is belangrijk. Bij conventionele systemen worden regels door een ontwikkelaar geschreven, bij machine learning worden die regels afgeleid uit patronen in trainingsdata. Dit maakt het mogelijk problemen op te lossen die te complex zijn voor handmatige regels, zoals beeldherkenning en spraaktranscriptie.
In zakelijke context is machine learning een instrument om onzekerheid te kwantificeren en beslissingen te ondersteunen. Succesvolle inzet vereist betrouwbare data, heldere KPI's en governance om risico's zoals datavervuiling of onbedoelde bias te beheersen.
Hoe werkt machine learning technisch
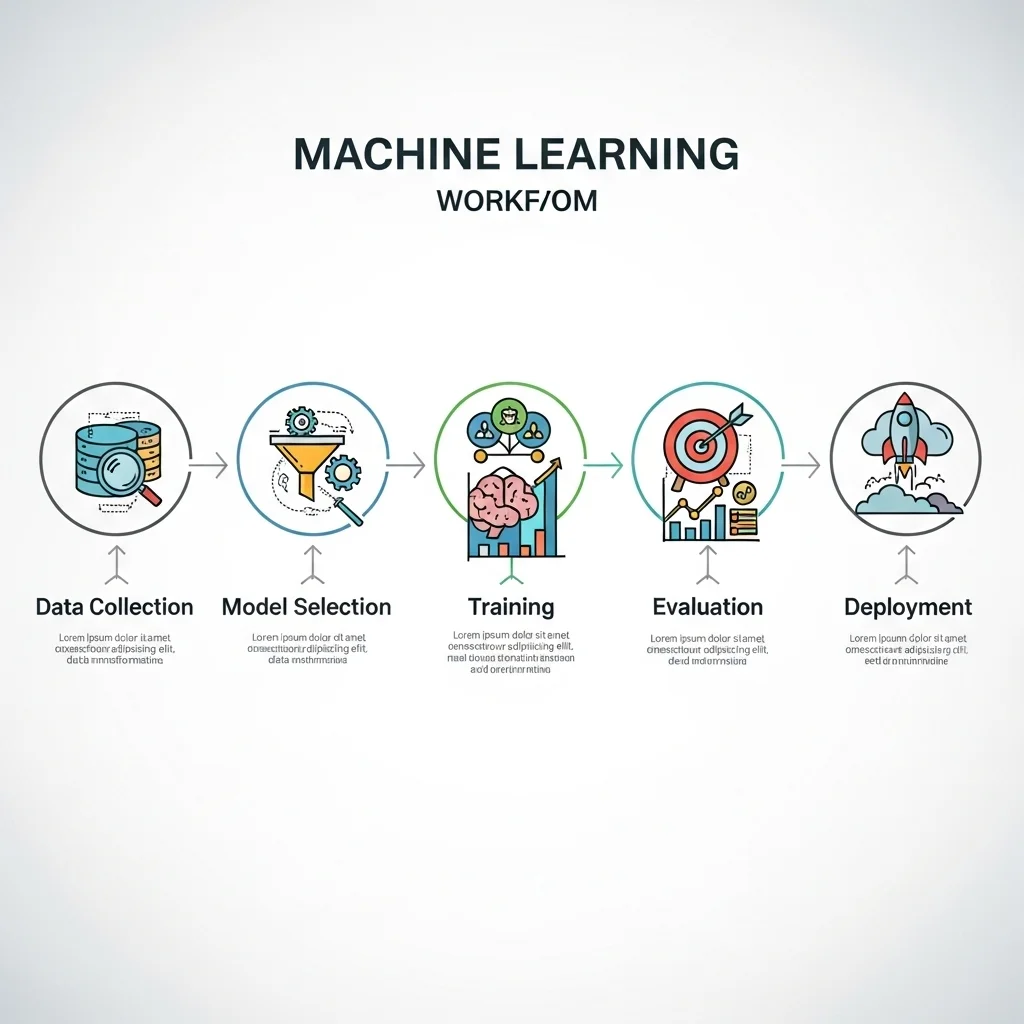
Het basisproces van machine learning bestaat uit data verzamelen, preprocessing, modelselectie, training, evaluatie en deployment. Data preprocessing omvat normalisatie, missing value handling en feature engineering, omdat ruwe data zelden direct bruikbaar is voor modeltraining.
Modellen variëren van eenvoudige lineaire regressies en decision trees tot geavanceerde neurale netwerken en transformer architecturen. Supervised learning gebruikt gelabelde voorbeelden, unsupervised learning zoekt structuren zonder labels, en reinforcement learning traint agents via beloningen. Evaluatie gebeurt met metrics zoals accuracy, precision, recall, F1-score en voor regressie RMSE of MAE, afhankelijk van de use case.
Een beknopt trainingsvoorbeeld in pseudocode toont de kernstappen van een supervised workflow:
data = load_dataset('train.csv')
features, labels = preprocess(data)
model = initialize_model('random_forest')
for epoch in range(1, N_epochs+1):
batches = create_batches(features, labels)
for X_batch, y_batch in batches:
model.train(X_batch, y_batch)
metrics = evaluate(model, validation_set)
deploy_if_satisfactory(model, metrics)
Dit illustreert dat het proces iteratief is en dat evaluatie op een onafhankelijke validatieset essentieel is om overfitting te detecteren.
Toepassingen, beperkingen en recente ontwikkelingen
Machine learning wordt toegepast in uiteenlopende domeinen, zoals gezondheidszorg, financiële dienstverlening, legal tech en productie. Typische voorbeelden zijn voorspellingen van klantgedrag, detectie van fraude en automatische documentanalyse. Binnen organisaties is het belangrijk om modulaire architecturen te hanteren, zodat modellen reproduceerbaar, auditeerbaar en updatebaar zijn.
Er bestaan duidelijke beperkingen. Modelbias, onvoldoende representatieve data en onduidelijke extrapolatie buiten de trainingsdistributie zijn reële risico's. Daarnaast is explainability van belang in gereguleerde sectoren. Governance en data-ethiek behoren integraal bij elk project.
Recente ontwikkelingen richten zich op schaalbaarheid, modelveiligheid en explainability. Er is intensieve discussie over de rol van grote taalmodellen in operationele systemen, inclusief kwaliteitscontrole en privacy. Binnen de laatste week is er in vakmedia en academische platforms aandacht geweest voor evaluatiepraktijken en verantwoorde inzet van grote modellen, en op de eigen site van Spartner is recent ingegaan op verwachtingen rond nieuwe LLM-releases in het artikel over Claude 4.5, wat relevant is voor organisaties die LLM-capaciteiten inbouwen. Voor organisaties die een start willen maken met AI en machine learning zijn de pagina's Starten met AI en AI content maken aanvullende bronnen.
Wat is het verschil tussen machine learning en klassieke statistiek?
Machine learning en klassieke statistiek delen veel methoden, maar hebben verschillende accenten. Statistiek legt nadruk op inferentie en verklarende modellen, vaak met expliciete assumpties. Machine learning focust meer op voorspelling en schaalbaarheid, met sterke nadruk op performance op nieuwe data. In de praktijk vullen beide disciplines elkaar aan.
Welke typen problemen zijn geschikt voor machine learning?
Problemen met voldoende gestructureerde data en een duidelijk gedefinieerd doel voor voorspelling of classificatie zijn geschikt. Typische voorbeelden zijn churn voorspelling, beeldclassificatie en tekstclassificatie. Problemen zonder voldoende data of met extreem hoge eisen aan verificatie kunnen beter met traditionele software of aanvullende data governance worden aangepakt.
Hoe wordt de kwaliteit van een model gemeten?
Kwaliteit wordt gemeten met data- en domeinspecifieke metrics. Voor classificatie zijn precision en recall relevant wanneer klassen ongelijk verdeeld zijn. Voor regressie worden RMSE en MAE gebruikt. Daarnaast is out-of-sample validatie cruciaal, en zijn technieken zoals cross validation, hold-out sets en A/B tests gangbare instrumenten. Een aparte evaluatie op productie-achtige data is vaak het meest waardevol.
Welke ethische en juridische risico's spelen bij machine learning?
Belangrijke risico's zijn bias in trainingdata, gebrek aan transparantie bij beslissingen en privacy van persoonsgegevens. Regelgeving zoals GDPR vereist zorgvuldige dataverwerking, en in bepaalde sectoren bestaan expliciete eisen aan uitlegbaarheid en auditability. Implementatie van logging, data lineage en toestemmingbeheer behoort tot best practices.
Moet een bedrijf eigen modellen bouwen of kant-en-klare LLM's gebruiken?
De keuze hangt af van de use case, datagevoeligheid en benodigde controle. Voor standaard taken kan het gebruik van bestaande LLM's of model-API's efficiënt zijn. Voor gevoelige data, maatwerkfunctionaliteit of compliance-eisen is een eigen model of private hosting vaak aangewezen. Voor organisaties die willen experimenteren zijn stappen zoals een data-audit en een proof-of-concept aan te raden.
Hoe zorgt men voor veilige, beheerste inzet van ML-modellen?
Veilige inzet vereist een combinatie van technische en organisatorische maatregelen, zoals model monitoring, retrainingstrategieën, rollback-procedures en toegangsbeheer. Daarnaast is het cruciaal om duidelijke acceptatiecriteria vast te leggen en de impact op bedrijfsprocessen te definiëren. Governance rond datakwaliteit en logging maakt onderdeel uit van compliance.
Wat zijn recente trends die relevant zijn voor machine learning projecten?
Recente aandachtspunten zijn betere evaluatiemetingen voor generatieve modellen, hulpmiddelen voor model explainability en frameworks voor model governance. In technische communities en vakpers wordt nadruk gelegd op robuustheid van LLM's in productieomgevingen en op methoden voor het detecteren van drift in modelperformance. Organisaties die LLM-functionaliteit integreren worden geadviseerd expliciet te documenteren welke modelversies en datasets worden gebruikt, en frequent te valideren tegen realistische scenario's. 😊