Overzicht
Retrieval augmented generation, vaak afgekort tot RAG, is een methode om grote taalmodellen te voorzien van actuele en domeinspecifieke kennis zonder het model zelf opnieuw te trainen. Het combineert informatieopslag en informatieopvraging met tekstgeneratie in een samenhangende pijplijn.
RAG wordt veel gebruikt voor zoekgestuurde chatbots, ondersteunende documentatie, klantenservice, juridische en medische vraagbeantwoording en analytische toepassingen bovenop private data. In plaats van dat een model uitsluitend vertrouwt op de statistische patronen uit de trainingsdata, kan het tijdens een vraag antwoord cyclus relevante documenten ophalen en gebruiken als feitelijke basis.
In dit artikel worden de belangrijkste begrippen rond RAG uitgelegd, waaronder de basisarchitectuur, het retrievalproces, de rol van vector databases en embeddings, de interactie met grote taalmodellen, verschillende RAG varianten en de voornaamste kwaliteits en veiligheidsaspecten.
Definitie en positionering van retrieval augmented generation
Retrieval augmented generation is een architectuurpatroon waarbij een generatief taalmodel tijdens het beantwoorden van een vraag expliciet toegang krijgt tot externe kennisbronnen. Die kennis kan bestaan uit documenten, webpagina's, handleidingen, e mails, productcatalogi, codebases of andere gestructureerde en ongestructureerde data. Het kernidee is dat het model niet alleen "uit zijn hoofd" antwoord geeft, maar eerst relevante informatie ophaalt en die als context gebruikt bij het genereren van tekst.
In een klassieke generatieve AI setting ontvangt het model een prompt en produceert het direct een antwoord, waarbij alle kennis uit de modelparameters komt. Bij RAG wordt tussen prompt en antwoord een retrievalstap ingevoegd. Deze stap zoekt in een aparte opslaglaag naar stukken informatie die passen bij de vraag. De gevonden fragmenten worden vervolgens toegevoegd aan de prompt richting het taalmodel. Hierdoor kan het model antwoorden die beter aansluiten bij de actuele en domeinspecifieke feiten die in de documenten staan.
RAG wordt vaak gepositioneerd als alternatief voor of aanvulling op het volledig fijnslijpen van een model met nieuwe trainingsdata. In plaats van het model opnieuw te trainen met grote hoeveelheden bedrijfsdata, blijven de documenten buiten het model opgeslagen. De combinatie van retrievallaag en generatief model vormt samen het systeem. Dit heeft belangrijke gevolgen voor beheer, schaalbaarheid, privacy en update snelheid van de kennis.
Een praktische toepassing van deze architectuur is een kennisgestuurde chatbot die zoekt in interne documentatie en beleidsteksten. De chatbot ontvangt de vraag van de gebruiker, zoekt in de documentcollectie naar gerelateerde passages, voegt die passages toe als context en genereert daarna een antwoord. In veel moderne bedrijfsoplossingen wordt deze RAG aanpak gecombineerd met bestaande webapplicaties, bijvoorbeeld gebouwd in Laravel of andere web frameworks.
Basisarchitectuur en datastroom in een RAG systeem
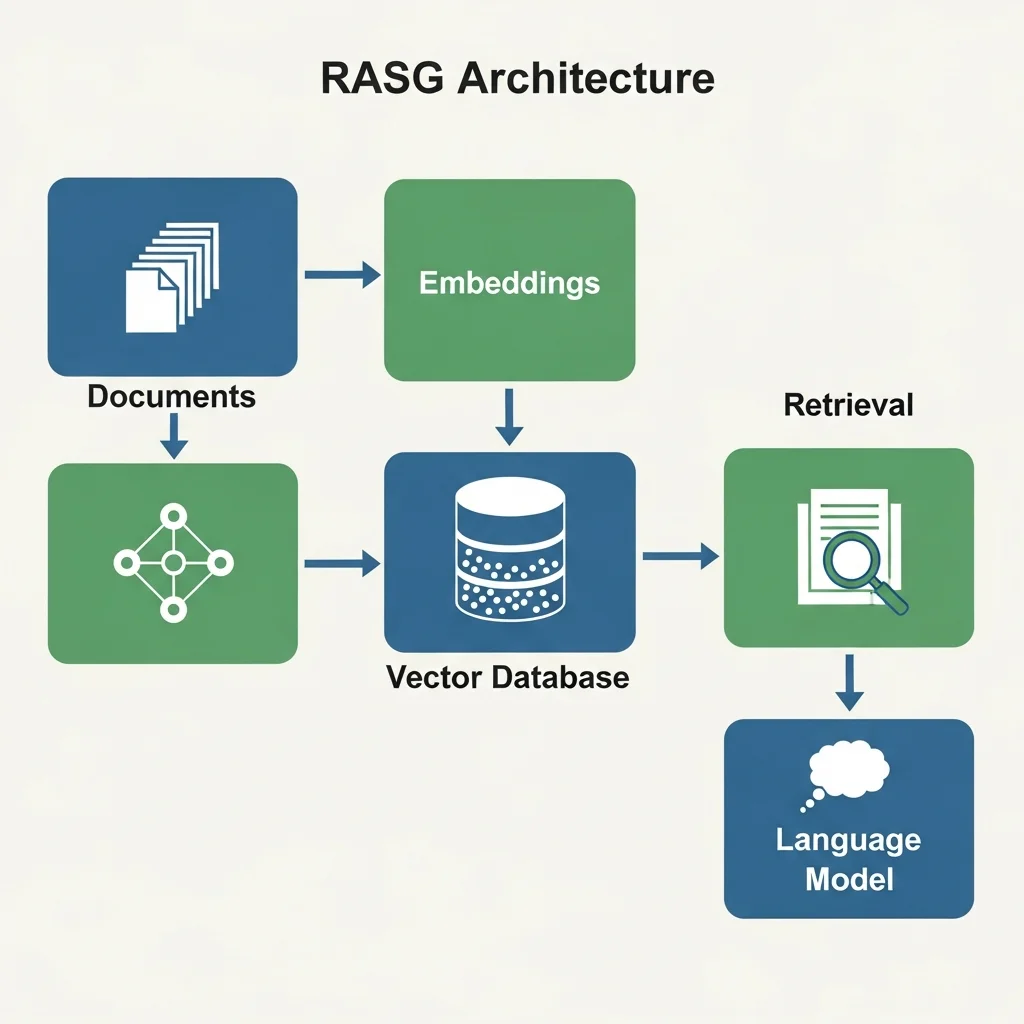
Een RAG systeem bestaat uit meerdere bouwstenen die samen de datastroom van vraag naar antwoord bepalen. De kerncomponenten zijn doorgaans een documentbron, een pre processing en chunkinglaag, een embeddingmodel, een vector index of vector database, een retrieval en rankinglaag en een generatief taalmodel. Daarnaast zijn er vaak aanvullende lagen voor logging, evaluatie, veiligheid en monitoring.
De typische datastroom begint bij de documenten. Tekstbronnen worden verzameld, opgeschoond en opgesplitst in kleinere tekstblokken, vaak "chunks" genoemd. Het doel van deze opdeling is dat elk chunk voldoende zelfstandig betekenis heeft en niet te lang is voor efficiënte opslag en latere contextinjectie. De chunks worden vervolgens omgezet in vectoren via een embeddingmodel. Dit zijn numerieke representaties die semantische overeenkomsten tussen teksten vastleggen.
De vectoren worden opgeslagen in een vector database of een andere vorm van index die snelle gelijkeniszoekopdrachten ondersteunt. Op dat moment is de basis voor retrieval gelegd. Wanneer een gebruiker een vraag stelt, wordt die vraag eveneens via hetzelfde of een compatibel embeddingmodel omgezet in een vector. Deze vraagvector wordt gebruikt om in de index te zoeken naar de meest vergelijkbare documentvectoren. De bijbehorende tekstchunks worden teruggehaald als kandidaten.
Daarna volgt vaak een re ranking of filteringstap, waarin aanvullende logica wordt toegepast, bijvoorbeeld op basis van metadata, tijdstempels, toegangsrechten of domeinregels. De geselecteerde documenten worden samengevoegd met de oorspronkelijke vraag tot een uitgebreide prompt die het generatieve taalmodel ontvangt. Het model genereert een antwoord waarin het probeert de informatie uit de opgehaalde documenten te integreren. Een belangrijk ontwerpprincipe is dat het model expliciet wordt geïnstrueerd om zich aan de gegeven bronnen te houden en om onzekerheid te melden als de bronnen geen duidelijk antwoord bieden.
Een veelgebruikte variatie op dit schema is multi turn conversatie, waarbij niet alleen de actuele vraag en de opgehaalde documenten, maar ook eerdere interacties worden meegenomen in de context. In zulke systemen moet zorgvuldig worden gekozen welke delen van de gespreksgeschiedenis worden bewaard in de prompt en welke alleen in de vector index worden opgeslagen. Ook toegang tot verschillende kennisdomeinen, bijvoorbeeld algemene encyclopedische kennis en zeer specifieke bedrijfsinformatie, kan via meerdere indices worden geregeld.
Varianten van RAG en relationele concepten
Er bestaan verschillende varianten van retrieval augmented generation die inspelen op andere typen gegevens, taken en architecturale voorkeuren. Een eerste onderscheid is dat tussen "naïeve RAG" en meer geavanceerde pipelines. In de eenvoudigste vorm worden slechts de top N documenten op basis van vectorafstand opgehaald en direct in de prompt gezet. In meer volwassen varianten wordt een cascade gebruikt waarbij eerst een brede selectie wordt opgehaald en daarna via re ranking, queryuitbreiding of logische filtering wordt verfijnd.
Een belangrijke variant is hybride retrieval. Hierbij wordt niet alleen gebruikgemaakt van vectorzoektechnologie, maar ook van klassieke zoekmethoden zoals omgekeerde indexen, trefwoordrangschikking en booleaanse filters. Door bijvoorbeeld BM25 en vectorzoekresultaten te combineren kan de robuustheid van de retrieval laag worden verhoogd, vooral in domeinen met korte queries of specifieke vakterminologie. Sommige systemen gebruiken contextuele uitbreidingen van de vraag, waarbij het taalmodel eerst helpt een betere zoekquery te formuleren voordat de feitelijke retrieval plaatsvindt.
Er zijn ook domeinspecifieke RAG varianten voor vakgebieden zoals gezondheidszorg, recht, engineering en financiën. In dergelijke domeinen worden vaak aanvullende regels toegepast om de resultaten te controleren. Een voorbeeld is een variant waarin de gegenereerde tekst na afloop wordt vergeleken met de bronpassages. Als het antwoord onvoldoende is terug te herleiden tot de bronnen, kan het worden afgekeurd of gemarkeerd als onzeker. Deze aanpak wordt soms "grounded generation" genoemd, omdat de uitvoer expliciet gegrond is in concrete bronnen.
RAG heeft bovendien verwantschap met concepten zoals retrieval based question answering, open domain QA en context augmented generation. Het onderscheidende kenmerk van moderne RAG architecturen is de nauwe koppeling aan grote taalmodellen en de inzet van embeddings voor semantische zoekopdrachten. De combinatie van deze technieken maakt dat systemen antwoorden kunnen formuleren in natuurlijke taal, terwijl zij toch aansluiten bij bedrijfsdocumenten en andere private data.
Voordelen, beperkingen en kwaliteitsaspecten
RAG biedt meerdere voordelen ten opzichte van generatieve systemen die uitsluitend op modelparameters vertrouwen. Een belangrijk voordeel is dat kennisbeheer en modelbeheer worden ontkoppeld. Nieuwe documenten kunnen worden toegevoegd aan de index zonder dat het taalmodel opnieuw hoeft te worden getraind. Dit maakt het mogelijk om de kennisbasis frequent bij te werken, wat essentieel is in domeinen met snel veranderende informatie zoals wetgeving, productdocumentatie of medische richtlijnen.
Een tweede voordeel is dat RAG kan helpen bij het beperken van "hallucinaties", het verschijnsel waarbij een model plausibel klinkende maar feitelijk onjuiste informatie produceert. Door het model bij de beantwoording expliciet te voorzien van relevante bronpassages, wordt de kans groter dat het antwoord inhoudelijk klopt. Bovendien kunnen systemen zo worden ingericht dat ze de gebruikte bronnen tonen, wat de transparantie en verifieerbaarheid verhoogt. Dit is belangrijk voor gebruikers die het antwoord willen controleren of verder willen verdiepen.
Daartegenover staan verschillende beperkingen en aandachtspunten. De kwaliteit van een RAG systeem hangt sterk af van de kwaliteit van de onderliggende documenten en de strategie voor segmentatie, indexing en ranking. Slecht gestructureerde of verouderde documenten kunnen leiden tot verkeerde of incomplete antwoorden. Ook het embeddingmodel speelt een rol: als dit model domeinspecifieke termen niet goed begrijpt, kan de retrievallaag relevante passages missen. Verder is er de uitdaging van contextlimieten van taalmodellen: er kan maar een beperkte hoeveelheid tekst in de prompt worden meegegeven. Dit vraagt om zorgvuldige selectie en samenvatting van documenten.
Kwaliteitsborging bij RAG systemen omvat doorgaans evaluatie op meerdere niveaus. Er wordt gekeken naar retrievalkwaliteit, bijvoorbeeld via maatstaven zoals recall en precision, en naar antwoordkwaliteit, bijvoorbeeld via menselijke beoordelingen of taak specifieke metrics. In gevoelige domeinen, zoals gezondheidszorg en juridische advisering, wordt vaak een mens in de lus gehouden. In zulke configuraties fungeert RAG als beslissingsondersteuning, niet als autonoom beslissingssysteem.
Ten slotte spelen privacy en gegevensbescherming een belangrijke rol. Omdat RAG systemen vaak toegang hebben tot vertrouwelijke bedrijfsdocumenten, moet worden gegarandeerd dat gegevens veilig worden opgeslagen en alleen toegankelijk zijn voor bevoegde gebruikers. Systemen kunnen zo worden ingericht dat de gebruikte taalmodellen geen gegevens hergebruiken voor eigen training. Daarnaast worden vaak beleidsteksten en technische maatregelen ingezet om te voorkomen dat gevoelige informatie ongewenst in antwoorden naar buiten komt.
Wat is retrieval augmented generation in eenvoudige bewoording?
Retrieval augmented generation is een techniek waarbij een taalmodel eerst relevante informatie uit een documentcollectie opzoekt en die informatie vervolgens gebruikt bij het formuleren van een antwoord. In plaats van alles uit de interne modelkennis te halen, combineert het systeem zoeken en genereren tot één geheel. Dit maakt antwoorden vaak actueler en beter herleidbaar.
Waarin verschilt RAG van een klassieke chatbot zonder retrievallaag?
Een klassieke chatbot werkt op basis van de interne kennis van het model en eventueel vaste dialoogregels, zonder tijdens het gesprek extra documenten op te zoeken. RAG voegt een aparte zoekstap toe, waarbij documenten worden opgehaald die specifiek bij de vraag passen. Daardoor kan een RAG chatbot bijvoorbeeld rechtstreeks citeren uit handleidingen, beleidsdocumenten of productinformatie en antwoorden geven die beter zijn afgestemd op de beschikbare kennis.
Waarom wordt RAG veel gebruikt bij bedrijfsdocumentatie en kennisbanken?
In organisaties verandert informatie geregeld, bijvoorbeeld door nieuwe procedures, producten of wetgeving. Met RAG kan de centrale documentatie up to date worden gehouden, terwijl het taalmodel hetzelfde blijft. Door documenten toe te voegen aan de index krijgt het systeem automatisch toegang tot de nieuwe kennis. Dit is efficiënter dan het model telkens opnieuw te trainen en verkleint het risico dat medewerkers met verouderde informatie werken.
Is RAG voldoende om hallucinaties van een taalmodel helemaal te voorkomen?
RAG kan de kans op hallucinaties aanzienlijk verlagen, maar voorkomt ze niet volledig. Het taalmodel blijft een probabilistisch systeem dat patronen in taal volgt en kan nog steeds fouten maken, bijvoorbeeld als de opgehaalde documenten onvolledig of ambigu zijn. In de praktijk worden daarom aanvullende maatregelen genomen, zoals instructies om bij onduidelijkheid "ik weet het niet" te antwoorden, post processingcontroles en soms een menselijke reviewstap bij kritieke beslissingen. 🙂
Welke rol speelt een vector database in een RAG architectuur?
Een vector database wordt gebruikt om numerieke representaties van tekst, de embeddings, op te slaan en te doorzoeken. Hierdoor kan het systeem op basis van semantische gelijkenis zoeken, dus niet alleen op exacte trefwoorden, maar ook op inhoudelijk verwante begrippen. Bij een vraag wordt een embedding van die vraag gemaakt en vergeleken met de embeddings van de documenten. De documenten met de meest vergelijkbare vectoren worden als context naar het taalmodel gestuurd. Zonder zo'n vectorindex zou semantisch zoeken op grote tekstcollecties veel minder efficiënt zijn.
Welke soorten data kunnen in een RAG systeem worden gebruikt?
In principe kan elke tekstvorm worden gebruikt, mits deze wordt geconverteerd naar doorzoekbare tekst. Dat kunnen webpagina's, PDF documenten, e mails, gesprekslogboeken, codefragmenten, productcatalogi of kennisartikelen zijn. In meer geavanceerde systemen worden ook tabellen, grafiekbeschrijvingen of gestructureerde databases meegenomen. Vaak worden deze diverse bronnen eerst gestandaardiseerd en verrijkt met metadata, zodat de retrievallaag beter kan filteren en rangschikken.
Is RAG alleen relevant voor grote organisaties met veel data?
RAG is zeker nuttig voor grote organisaties met uitgebreide documentcollecties, maar ook kleinere organisaties kunnen voordeel hebben. Zelfs met een relatief beperkte set documenten kan een RAG systeem helpen om consistente en snel terugvindbare antwoorden te geven op veelgestelde vragen. De implementatieschaal verschilt, maar de onderliggende principes, het combineren van zoeken en genereren, blijven hetzelfde. Voor kleinere omgevingen is het vooral belangrijk om de setup eenvoudig en onderhoudbaar te houden.